- Kärnminnesdumpar registrerar systemtillståndet vid kritiska fel och är viktiga för felsökning och säkerhetsgranskning.
- I Windows analyseras de med WinDbg eller KD, med hjälp av symboler och kommandon som !analyze -vy .bugcheck för att lokalisera drivrutiner och orsaker till felet.
- I Linux låter verktyg som crash, LiME och gcore dig extrahera och studera kärn- och processdumpar, med särskild vikt vid att skydda känsliga data.
- FreeBSD och andra Unix-system kräver kärnor kompilerade med symboler och användning av kgdb, och förlitar sig alltid på dokumentation och källkod för att tolka resultaten.
När ett operativsystem får panik eller kraschar spektakulärt är det enda sättet att förstå vad som hände att... kärnminnesdump och efterföljande analysDessa dumpfiler fångar systemets interna tillstånd vid felögonblicket och är råmaterialet för att felsöka komplexa fel, utreda säkerhetsincidenter eller utföra kriminaltekniska undersökningar.
Även om det kan låta väldigt "lågnivå" är det inte bara kärnutvecklare som kan analysera en minnesdump. Systemadministratörer, supportingenjörer och även säkerhetsrevisorer kan dra nytta av det om de känner till grunderna. lämpliga verktyg, typer av dumpar och grundläggande tolkningsteknikerVi kommer att täcka hela den här processen i Windows, Unix/Linux och BSD, med hjälp av verktyg som WinDbg, crash, kgdb och LiME.
Vad är en kärnminnesdump och varför är den värd att analysera?
En kärnminnesdump (ofta kallad Kärnkraschdump eller helt enkelt kraschdump) är en fil som innehåller en kopia, helt eller delvis, av minnet i det ögonblick då systemet drabbas av ett kritiskt fel, till exempel ett kärnan panik i Unix/Linux eller en blåskärm (BSOD) i Windows.
I praktiken sparar en dump av den här typen interna kärnstrukturer, anropsstackar, processkontext och laddade drivrutinerTack vare detta kan en "post mortem"-analys göras efter katastrofen, mycket likt felsökning av ett live-system, men utan pressen att behöva röra en produktionsmaskin medan den går sönder.
Skälen till att fördjupa sig i kärndumpar är varierande: från felsöka till synes slumpmässiga buggar och intermittenta krascher...till och med undersöka om ett system har blivit illvilligt manipulerat eller om en krasch kan ha lämnat spår av känslig information på disken.
Förutom fullständiga kärndumpar finns det möjlighet att extrahera dumpar av enskilda processer (den klassiska kärndumpar), vilket är mycket användbart när det vi vill ha är att begränsa ett problem till en specifik applikation eller att granska effekten på en tjänsts sekretess som en e-post- eller meddelandeklient.
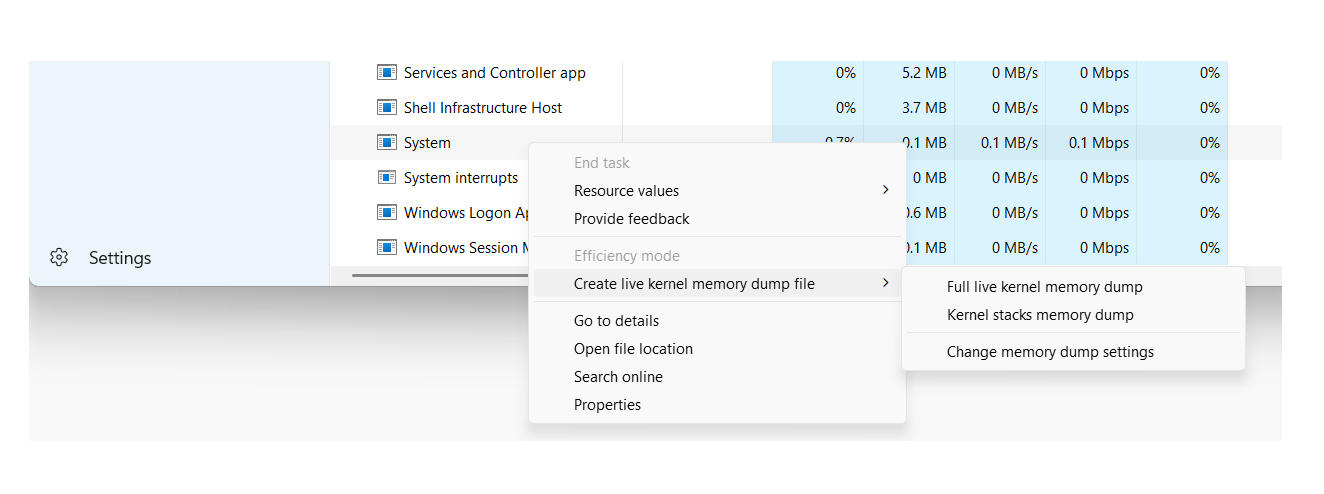
Typer av minnesdumpar i Windows och deras användbarhet
På Windows-system kan själva operativsystemet generera olika typer av dumpfiler när ett STOP-fel uppstår. Varje typ har en annan detaljnivå, så det är viktigt att veta vilka man ska använda. Vilken typ av dump behöver vi baserat på problemet och begränsningarna i diskutrymmet?.
Ett av de vanligaste formaten i användarmiljöer och på många servrar är liten minnesdump (minidump)Det är den som tar minst plats och är vanligtvis placerad i %SystemRoot%\Minidump, med filer av stilen MiniMMDDÅÅ-01.dmp.
Denna minidump innehåller mycket specifik men viktig information: STOP-felkod och dess parametrar, listan över drivrutiner som laddades vid tidpunkten för felet, kontexten för processorn som stoppades (PRCB), kontexterna för den involverade processen och tråden (EPROCESS- och ETHREAD-strukturer) och kernel-mode-anropsstacken för den tråden.
Tack vare dessa grundläggande strukturer är det ofta möjligt att även med en minidump identifiera vilken drivrutin eller modul som orsakar krascherna, även om det inte alltid är möjligt att spåra hela problemet om det har sitt ursprung långt ifrån den tråd som kördes vid tidpunkten för kraschen. Tillgänglig kontextuell information är begränsad.
Windows kan också generera kärnminnesdumpar och mycket större fullständiga dumpar som innehåller delar av eller allt fysiskt minne. Dessa är särskilt användbara i lågnivåanalys, forensiska undersökningar och avancerad felsökning av drivrutiner eller själva systemet.
Konfigurera och öppna minnesdumpar i Windows med WinDbg och KD
För att dra nytta av dumpfiler i Windows är det första som krävs att alternativen är korrekt konfigurerade. uppstart och återställningFrån Kontrollpanelen, i de avancerade systemegenskaperna, kan du välja vilken typ av dump du vill generera vid ett fel: till exempel "Liten minnesdump (256 KB)" och sökvägen där den ska lagras.
Systemet behöver också en personsökningsfil på startvolymen på minst några megabyte för att skriva dumpfilen. I moderna versioner av Windows skapar varje krasch en ny fil och en historik sparas i den konfigurerade mappen, vilket möjliggör enkel granskning av tidigare incidenter.
När dumparna väl har genererats finns det flera sätt att validera att de är korrekta. Ett klassiskt verktyg är Dumpchk.exevilket låter dig kontrollera filens grundläggande integritet och skriva ut sammanfattningsinformation. För mer avancerad analys används följande: Felsökningsverktyg för Windowssom inkluderar WinDbg (grafiskt gränssnitt) och KD (kommandoradsversion).
Efter att du har installerat felsökningspaketet från Microsofts webbplats finns verktygen vanligtvis i en mapp som C:\Programfiler\Felsökningsverktyg för WindowsDärifrån kan vi öppna en kommandotolk och ladda en dump med WinDbg eller KD med hjälp av parametern -z för att ange filen:
windbg -y <RutaSimbolos> -i <RutaBinarios> -z <RutaDump>
Symbolvägen kan peka på en symbolserver med lokal cache, till exempel:
srv*C:\Symbols*https://msdl.microsoft.com/download/symbols
Medan den binära sökvägen vanligtvis är något i stil med C:\Windows\I386 eller mappen dit vi har kopierat de körbara filerna som motsvarar den version som genererade dumpfilen. Detta är viktigt eftersom Minidumps inkluderar inte alla binärfiler, bara referenser till dem, så felsökaren måste kunna hitta dem.
Grundläggande analys av en kärnkraschdump i Windows
När dumpen väl har laddats med WinDbg eller KD, är analys av en kärnkraschdump ganska likt en felsökningssession efter döden. Det första kommandot som nästan alla kör är !analysera, vilket startar en automatisk analys och genererar en första rapport.
Kommandot !analyze -show visar buggkontrollkod och dess parametrarMedan !analyze -v Den producerar en mycket mer detaljerad utdata: misstänkt modul, anropsstack, kontextuell information och, i många fall, förslag på möjliga orsaker eller diagnostiska steg.
För att komplettera den analysen, kommandot .bugcheck Den skriver ut felkoden och tillhörande parametrar igen, vilka sedan kan jämföras med referens för buggkontrollkod från Microsoft för att lära sig den exakta betydelsen av varje värde och de typiska orsakerna.
Kommandot lm N T (lista moduler) låter dig se Lista över laddade moduler med deras sökväg, adresser och statusDetta hjälper till att bekräfta om drivrutinen som identifierats av den automatiserade analysen faktiskt finns i minnet och vilken version den har. Den här listan är särskilt användbar när vi misstänker att drivrutiner eller säkerhetskomponenter från tredje part interagerar med kärnan.
Om så önskas kan vi förenkla lastningsprocessen genom att skapa en batchfil Den tar emot sökvägen till dumpfilen och startar KD eller WinDbg med lämpliga parametrar. På så sätt behöver du bara skriva ett kort kommando som inkluderar filens plats, och skriptet tar hand om allt annat.
Använda WinDbg för djupa kärndumpar
För minnesdumpar i kärnläge erbjuder WinDbg även möjligheten att arbeta med flera filer och sessioner. Dumpar kan öppnas från kommandoraden med -zeller från det grafiska gränssnittet, med hjälp av menyn Arkiv > Öppna minnesdump eller kortkommandot Ctrl + D.
Om WinDbg redan är öppet i passivt läge, välj helt enkelt filen i dialogrutan "Öppna kraschdump", ange sökvägen eller bläddra på disken. När den är laddad kan vi starta sessionen med ett kommando. g (Gå) i vissa scenarier, eller direkt starta de första analyskommandona.
Förutom den klassiska !analyzeDet är lämpligt att bekanta sig med referensavsnitt för felsökarkommandonDetta beskriver alla tillgängliga kommandon för att läsa interna strukturer, undersöka minne, tolka stackar och mycket mer. Många av dessa tekniker är tillämpliga på både live-sessioner och offline-dumpar.
WinDbg låter dig också arbeta med flera parallella dumparVi kan lägga till flera -z-parametrar på kommandoraden, var och en följt av ett annat filnamn, eller lägga till nya mål med hjälp av kommandot .opendumpFelsökning av flera destinationer är användbart för att jämföra återkommande fel eller länkade incidenter.
I vissa miljöer paketeras minnesdumpar i CAB-filer för att spara utrymme eller underlätta överföring. WinDbg kan öppna en .cab med en dump inuti, både med -z och med .opendumpäven om han kommer att läsa Den kommer bara att extrahera en av de dumpade filerna och kommer inte att extrahera andra filer. som skulle kunna gå i samma paket.
Kraschdumpar i Unix och Linux: verktyg, verktyg och krav
I Unix- och GNU/Linux-system är filosofin likartad, men ekosystemet av verktyg skiljer sig avsevärt. De flesta Unix-liknande kärnor erbjuder möjligheten att spara en kopia av minnet när en katastrofal händelse inträffar, vad vi känner som kärndump eller kärnkraschdump.
Även om deras primära användning fortfarande är kärn- och drivrutinsutveckling, har dessa dumpfiler en tydlig säkerhetsaspekt. En krasch kan orsakas av programmeringsfel, men även skadliga handlingar misslyckade försök att manipulera systemkomponenter eller klumpigt utnyttjade kapplöpningsförhållanden.
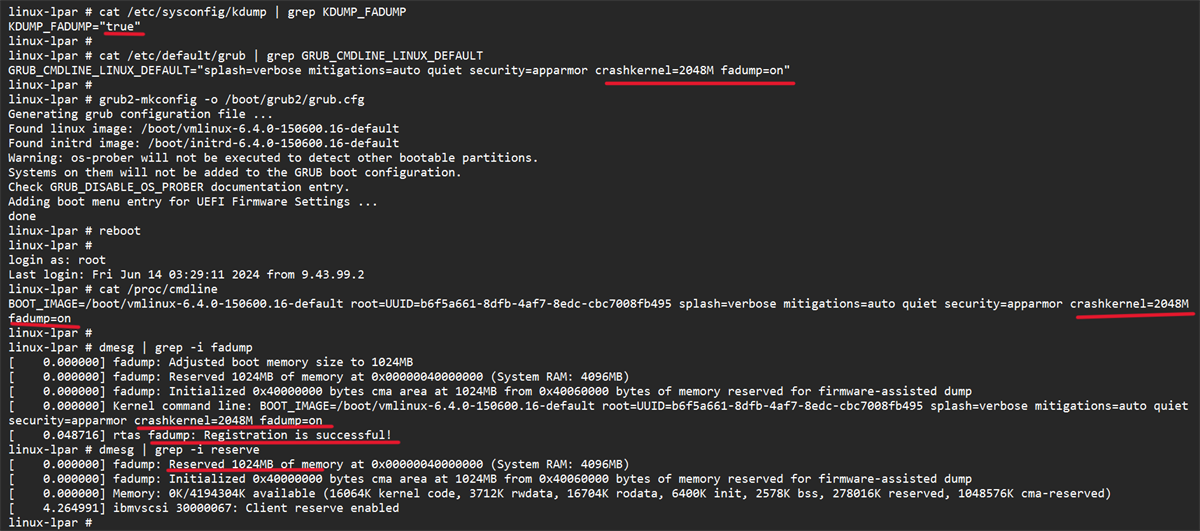
I ett välkonfigurerat Unix-system är dagliga krascher inte vanliga, men när de inträffar är det klokt att ha en reservplan på plats. dumpningsinfrastruktur som Kdump, LKCD eller andra lösningar som tillåter att fånga systemminne. Det är dock nödvändigt att väga både dumpens diagnostiska värde och risken för att den innehåller mycket känsliga data.
Ett av de mest kompletta och utbredda verktygen för den här typen av analys i Linux är kraschUrsprungligen utvecklat av Red Hat, har detta verktyg blivit en de facto-standard för att undersöka kerneldumps och analysera körbara system.
Kraschen kan påverka systemets liveminne genom /dev/mem eller, i Red Hat och derivatdistributioner, med hjälp av den specifika enheten /dev/crashÄndå är det vanligt att mata verktyget med en dumpfil som genereras av mekanismer som Kdump, makedumpfile, Diskdump eller arkitekturspecifika dumpfiler som s390/s390x eller xendump i virtualiserade miljöer.
Kraschens roll och vikten av vmlinux i Linux
Kraschverktyget skapades delvis för att övervinna begränsningarna med att använda gdb direkt på /proc/kcoreBland annat kan åtkomsten till den där minnespseudoavbildningen vara begränsad, och dessutom gör vissa kärnkompileringsalternativ det svårt att korrekt tolka de interna strukturerna om vi bara har den komprimerade körbara binärfilen.
För att kraschen ska fungera korrekt är två viktiga element nödvändiga: a vmlinux-fil kompilerad med felsökningssymboler (vanligtvis med flaggor som -g) och själva kärndumpen. Denna kombination gör att verktyget kan mappa minnesadresser till funktioner, strukturer och kodrader.
Det är viktigt att skilja på vmlinux och vmlinuzPå de flesta system syns endast vmlinux, vilket är en komprimerad, startbar version av kärnan. Krasch kräver den symboliskt dekomprimerade vmlinux; utan den, när man försöker ladda en dump eller /dev/mem Vi kommer att stöta på fel av typen kan inte hitta startad kärna — vänligen ange namnlistargumentet.
Även om det är möjligt att manuellt dekomprimera vmlinuz är processen inte alltid enkel och i praktiken oftast mycket bekvämare. Kompilera om kärnan för att hämta både vmlinux och vmlinuz parallellt. I seriösa administrationsmiljöer är det god praxis att underhålla vmlinux som motsvarar varje kärnversion som distribueras just för dessa fall.
När kraven är uppfyllda är det relativt enkelt att krascha en dumpfil: du anger lämplig vmlinux- och dumpfil, och verktyget öppnar en interaktiv session från vilken du kan gå igenom kärnstrukturer, lista processer, visa anropsstackar och extrahera forensisk informationDe som vill fördjupa sig ännu mer kan konsultera specialiserad dokumentation, såsom den välkända tekniska kraschrapporten.
Begränsningar med /dev/mem och första metoderna i Linux
Innan de tillgripit specifika verktyg har många administratörer historiskt sett försökt att få tag på en minnesdump. läser direkt från enheten /dev/memDen här metoden verkade enkel: använd ett verktyg som memdump (vilket dumpar den enheten till STDOUT) eller hämtar från dd if=/dev/mem of=volcado.mem.
Moderna kärnor erbjuder dock kompileringsalternativ som CONFIG_STRICT_DEVMEMvilket kraftigt begränsar åtkomsten från användarutrymmet till /dev/memDet typiska resultatet är att läsningen avbryts efter ett litet block (t.ex. 1 MB) eller, i värsta fall, att en bugg i den interaktionen kan sluta i en kärnan panik omedelbart och omstart av maskinen.
Detta skydd är helt logiskt ur säkerhetssynpunkt, men det tvingar oss att leta efter Andra sätt att få en pålitlig och komplett dumpning utan att helt förlita sig på generiska enheter som inte längre är lika tillgängliga som tidigare.
Därför är den nuvarande trenden att förlita sig på specifika moduler eller integrerade kraschdumpinfrastrukturer, istället för att helt enkelt försöka "skrapa minne" med användarutrymmesverktyg som inte är utformade för att samexistera med moderna kärnskyddspolicyer.
LiME Forensics: Minnesutvinning i Linux och Android
Ett mycket kraftfullt alternativ inom forensikvärlden är LiME (Linux-minnesutdragare)LiME är en kärnmodul utformad specifikt för att fånga upp flyktigt minne på ett kontrollerat sätt och utan de begränsningar som påverkar /dev/mem. LiME körs i kärnutrymmet, så den kan komma åt RAM mycket mer direkt.
LiME distribueras med sin källkod och kompileras mot kärnhuvuden som användsKompileringsprocessen genererar en modul .ko specifikt för den kärnversion den ska laddas till. När den har kompilerats kan vi verifiera den med verktyg som file för att säkerställa att ELF-modulen som motsvarar vår arkitektur har genererats korrekt.
För att använda LiME, ladda helt enkelt modulen med insmod från roten och skicka den lämpliga alternativ, till exempel genom att ange en nätverksdumpdestination med TCP och ett råformat:
insmod lime-3.x.y.ko "path=tcp:4444 format=raw"
Parallellt, på maskinen som ska ta emot dumpen, lyssnar vi på den konfigurerade porten med hjälp av ett verktyg som ncomdirigera utdata till en fil:
nc <IP_origen> 4444 > volcado.mem
Efter några minuter, beroende på mängden RAM och nätverksprestanda, kommer vi att ha en fil vars storlek matchar källsystemets fysiska minne. Detta är en en komplett RAM-dump som vi kan analysera med forensiska verktyg eller till och med med strängar eller andra verktyg som ett första steg för att hitta intressanta kedjor.
Processdumpar och risker för dataexponering
En fullständig kerneldump är extremt informativ, men den kan också vara överdriven när vi bara är intresserade av en specifik process. I så fall är det mycket vettigt att ta till... individuella processdumpar med hjälp av verktyg som gcore i Unix/Linux.
Dessa dumpfiler per process är mycket mindre och mer hanterbara, och låter dig fokusera analysen på specifika applikationer som en meddelandeklient (till exempel Skype) eller en e-postklient (som Thunderbird), där det är relativt lätt att hitta. lösenord i klartext, sessionstokens eller kontaktuppgifter om minnessträngarna utforskas.
Ur ett utvecklingsperspektiv hjälper dessa kärndumpar till att lokalisera programmeringsfel, minnesläckor eller inkonsekventa tillstånd i en tjänst. Men ur ett säkerhetsperspektiv uppstår problemet när Dumparna genereras rutinmässigt och lagras på platser som är tillgängliga för andra användare.antingen på själva systemet eller på delade nätverksresurser.
Om en användare schemalägger, till exempel, en uppgift cron Genom att regelbundet samla in dumpfiler av känsliga processer och lämna dem i en globalt läsbar katalog öppnar en angripare en enorm dörr för exponering av kritisk information. I många granskningsscenarier gör analys av dessa filer det möjligt för en angripare att återställa sig. inloggningsuppgifter, kontaktlistor, kommunikationshistorik och annan privat information med relativt låg ansträngning.
Därför är det, vid all seriös granskning av ett Unix-system, lämpligt att ägna några minuter åt att kontrollera om dumpfiler (hela eller delvisa) genereras, var de lagras, vilka behörigheter de har och om det finns några. en automatiserad process som lämnar minneskopior åtkomliga för obehöriga användare.
Obduktionsanalys av dumpfiler i FreeBSD med kgdb
I BSD-världen, och specifikt i FreeBSD, innebär tillvägagångssättet för post mortem-analys Aktivera kraschdumpar på systemet och kompilera en kärna med felsökningssymbolerDetta styrs från kärnans konfigurationskatalog, vanligtvis i /usr/src/sys/<arq>/conf.
I motsvarande konfigurationsfil kan symbolgenerering aktiveras med en rad som denna:
makeoptions DEBUG=-g # Build kernel with gdb(1) debug symbols
Efter att konfigurationen har ändrats måste kärnan kompileras om. Vissa objekt kommer att regenereras (t.ex. trap.o) på grund av ändringen i byggfilerna. Målet är att få en kärna med samma kod som den som har problem, men med tillägg av nödvändig felsökningsinformationDet är lämpligt att jämföra de gamla och nya storlekarna med hjälp av kommandot size för att säkerställa att det inte har skett några oväntade ändringar i binärfilen.
När kärnan är installerad med symboler kan vi nu undersöka dumparna med kgdb som beskrivs i den officiella dokumentationen. Alla symboler kanske inte är kompletta, och vissa funktioner kan visas utan radnummer eller argumentinformation, men i de flesta fall är detaljeringsnivån tillräcklig för att spåra problemet.
Det finns ingen absolut garanti för att analysen kommer att lösa alla incidenter, men i praktiken, Denna strategi fungerar ganska bra i en hög andel scenariersärskilt när kraschdumpar kombineras med en bra granskning av de senaste systemändringarna.
Bästa praxis för att analysera och dokumentera kärnfel
Oavsett operativsystem leder kärndumpanalys vanligtvis till teknisk dokumentation, kunskapsbaser, specialiserade forum eller till och med själva kärnkällkoden för att tolka meddelanden, felkoder och okända symboler.
I Linux är det mycket bra att förlita sig på det officiella källkodsträdet, den inbyggda dokumentationen och community-resurser. Många kärnfelmeddelanden kan spåras tillbaka till exakt den fil där de kommer från, vilket hjälper till att förstå problemet. kontext där en BUG() eller WARN() utlöses fast besluten.
I Windows ger Microsofts dokumentation, kunskapsbas (KB) och tekniska forum detaljerade förklaringar av buggkontrollkoder, lösningsrekommendationer och kända felmönsterGenom att kombinera den informationen med !analyze -v-rapporterna är det möjligt att utarbeta en rimlig åtgärdsplan.
Det verkliga värdet av en kraschdump framträder när all den informationen jämförs med gedigen kunskap om operativsystemet och den specifika miljö där felet inträffadeEndast på detta sätt kan varaktiga lösningar föreslås och framför allt förhindra att samma problem återkommer i framtiden med allvarligare konsekvenser.
Analys av kärnminnesdumpar är i slutändan en blandning av vetenskap och hantverk: det kräver lämpliga verktyg, förhandskonfiguration (symboler, dumpalternativ, säker lagring) och en hel del erfarenhet av att läsa stackar, strukturer och felkoder. Att behärska dessa tekniker gör att du inte bara kan felsöka komplexa incidenter, utan också för att drastiskt öka säkerhetsnivån och motståndskraften i de system vi hanterar.
Innehållsförteckning
- Vad är en kärnminnesdump och varför är den värd att analysera?
- Typer av minnesdumpar i Windows och deras användbarhet
- Konfigurera och öppna minnesdumpar i Windows med WinDbg och KD
- Grundläggande analys av en kärnkraschdump i Windows
- Använda WinDbg för djupa kärndumpar
- Kraschdumpar i Unix och Linux: verktyg, verktyg och krav
- Kraschens roll och vikten av vmlinux i Linux
- Begränsningar med /dev/mem och första metoderna i Linux
- LiME Forensics: Minnesutvinning i Linux och Android
- Processdumpar och risker för dataexponering
- Obduktionsanalys av dumpfiler i FreeBSD med kgdb
- Bästa praxis för att analysera och dokumentera kärnfel