- Metin, resim, ses ve video içeren, gerçek zamanlı yayın yapan yerel çok modlu model.
- SOTA 22/36 ses/görüntü kıyaslamasında ve çok dilli (119/19/10 dil).
- MoE, düşük gecikme ve sistem istemi kontrolüne sahip Düşünen-Konuşan mimarisi.
- vLLM/Transformers, Docker ve resmi yardımcı programlarla birlikte kullanılması önerilir.
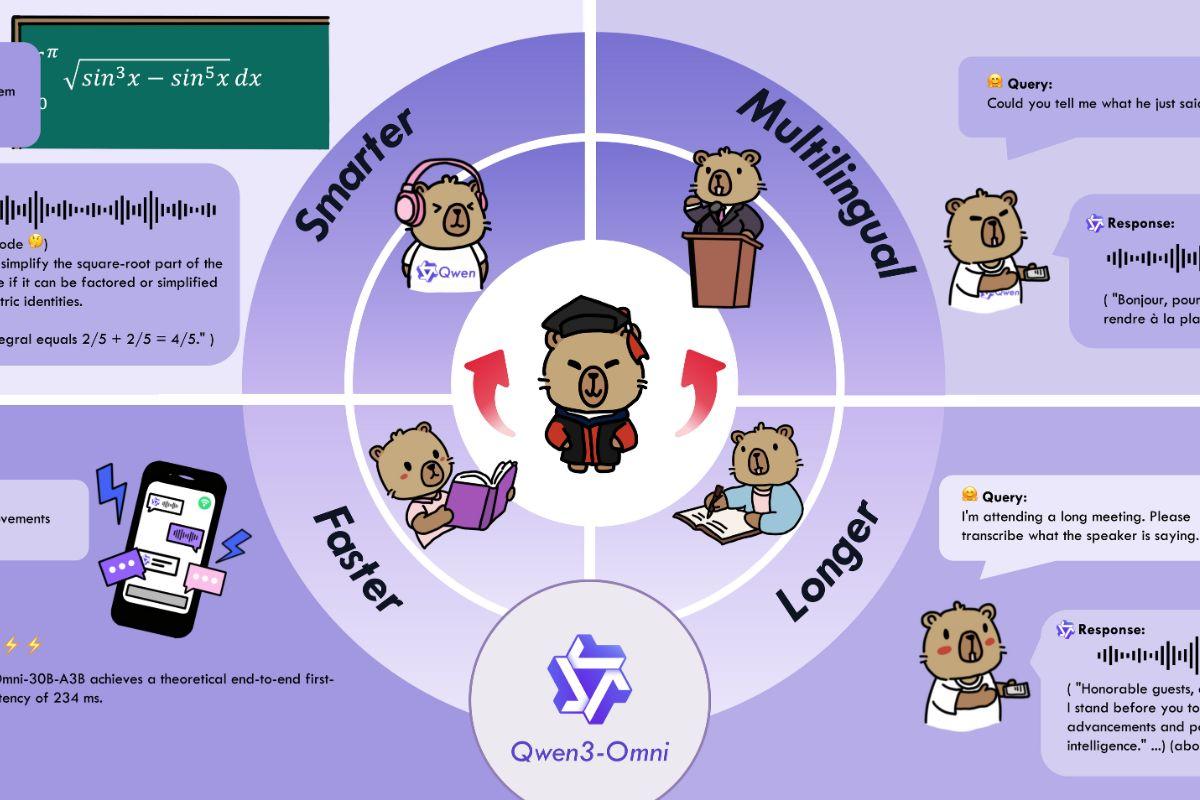
Qwen3-Omni'nin gelişi AI panosunda bir hamle yaptı: metin, resim, ses ve videoyu anlayıp yanıtlayabilen tek bir yerel model, hem yazılı hem de sözlü anında yanıtlarla. Çok modlu "yamalardan" değil, modları entegre etmek için sıfırdan tasarlanmış bir mimariden bahsediyoruz. düşük gecikme ve hassas davranış kontrolü.
Hemen hemen herkesin chatbot ve asistanları denediği bir dönemde Qwen3-Omni iddialı bir şekilde geliyor: Metin için 119 dili destekler, 19 dilde sesi tanır ve 10 dilde konuşur, uzun ses kayıtlarını (30 dakikaya kadar) anlar ve düzinelerce kıyaslamada referans ölçümleri sunar. Ayrıca, Düşünen-Konuşan tasarımı ve Uzmanların Karışımı yaklaşımı, tepki hızı ve muhakeme kalitesi gerçek yaşam senaryolarında.

Qwen3-Omni nedir ve neler sunar?
Qwen3‑Omni, uçtan uca "omnimodal" ve çok dilli temel modellerden oluşan bir ailedir. metin, resim, ses ve videoyu işlemek üzere tasarlanmıştır Hem metin hem de doğal ses çıktısı ile. Önemli olan sadece giriş ve çıkışların çeşitliliği değil, aynı zamanda bunların nasıl çalıştığıdır. Akıcı konuşma dönüşleriyle akış ve anında yanıt verebilme yeteneği.
Ekip, performans ve verimlilik için çeşitli mimari iyileştirmeler sundu: erken "metin odaklı" ön eğitim Karma çok modlu eğitim ve metin ve görseldeki yazıyı korurken ses ve görsel-işitselliği artıran MoE (Uzman Karışımı) ile bir tasarımla birleştirildi. Bu sayede model, 36 ses/video kıyaslamasının 22'sinde SOTA'ya ulaştı ve SOTA açık kaynaklı 36'dan 32'sinde yer aldı ve sonuçlar ASR, ses anlayışı ve sesli konuşmada Gemini 2.5 Pro ile karşılaştırılabilir.
Temel yetenekler ve yöntemler
Qwen3‑Omni, kapsamlı çok dilli desteğiyle gerçek hayattaki ses, görüntü ve görsel-işitsel kullanım durumlarına hazır olarak gelir: 119 metinden sese dil, 19 sesten sese giriş dili ve 10 sesten sese çıkış diliSes girişi dilleri arasında İngilizce, Çince, Korece, Japonca, Almanca, Rusça, İtalyanca, Fransızca, İspanyolca, Portekizce, Malayca, Felemenkçe, Endonezyaca, Türkçe, Vietnamca, Kantonca, Arapça ve Urduca; çıkış dilleri arasında ise İngilizce, Çince, Fransızca, Almanca, Rusça, İtalyanca, İspanyolca, Portekizce, Japonca ve Korece yer alıyor.
Resmi yemek kitabı paketi, kullanım alanlarının genişliğini göstermektedir. Sesli versiyon ise şunları göstermektedir: Çok dilli ve uzun sesli konuşma tanıma (ASR), ses-metin ve ses-ses çevirisi, müzik analizi (stil, ritim, türler), ses efektlerinin tanımı ve herhangi bir sesin altyazısıAyrıca ses, müzik ve ambiyans içeren parçaların karışık analizini de destekler.
Vizyonda karmaşık görüntüler için "sert" OCR vardır, nesne algılama ve topraklama, Görüntülerde QA, matematik çözümü görüntüde (Düşünme modelinin parladığı yer), video açıklamasında, birinci şahıs video tabanlı gezinmede ve sahne geçiş analizi. Görsel-işitsel senaryolarda, zaman uyumu ile ses-görüntü kalite güvencesini gösterir, AV girişleriyle yönlendirilen etkileşim ve yardımcı davranışlı diyaloglar.
Bir ajan olarak, yeteneğiyle öne çıkıyor sesten fonksiyon çağırma, araçları etkinleştiren sesli iş akışlarını açar ve türetilmiş görevlerde bir Omni-Captioner Temelin genelleme kapasitesini gösteren ayrıntılı bir altyazıya yer vermek gerekirse;
MoE ile Düşünen-Konuşan Mimarlık ve Tasarım
Farklılaştırıcı fikirlerden biri sorumlulukları ayırmaktır: Düşünen metni üretir (açık düşünce zinciri akıl yürütmesi olan varyantlarla) ve Talker ses üretir Gerçek zamanlı olarak. Bu ayrıştırma, sistem bir ses sinyalini korurken doğal sesli görüşmeye olanak tanır. yüksek düzeyde anlayış ve planlama metinde.
MoE tabanı, yükü uzmanlar arasında dağıtır ve güçlü genel temsiller için AuT ön eğitimine güvenir. Ayrıca, çoklu kod kodlama Ses kanalında gecikmeyi en aza indirir, bu da her birinin çağrılar veya asistanlar için önemli bir şeydir saniyenin yüzde biri hesap.
Performans ve kıyaslamalar: metin, görüntü, ses ve görsel-işitsel
Qwen3-Omni, tek bir moda odaklanan aynı boyuttaki Qwen modellerine kıyasla bozulmadan en son metin ve görüntü performansını korurken, ses ve görsel-işitsel performansta çoğu testte tempoyu belirler36 ses ve görsel-işitsel kıyaslama pilinde 32'sinde açık kaynaklı SOTA'ya ve 22'sinde toplam SOTA'ya ulaşarak birkaç puan geride bıraktı Gemini 2.5 Pro ve GPT‑4o.
Metindeki bazı önemli noktalar: AIME25 Flash-Instruct varyantı yaklaşık 65,9'dur; ZebraLogic Talimat 90'a ulaşır ve Çoklu GPT-4o ile karşılaştırıldığında rekabetçi rakamlara ulaşır. IFEval ve WritingBench gibi hizalama görevlerinde, Talimat ve Düşünme modelleri yüksek ve tutarlı puanlar gösterir.
Seste, Çince ve İngilizce için ASR sonuçları mükemmeldir: WenetSpeech y librikonuşma LibriSpeech temiz/diğer ve şu gibi setlerde kelime hata oranını 1,22/2,48'e yakın rakamlarla önemli ölçüde azaltır ÇİÇEKLER (çok dilli) çok düşük fiyatlar sunar. VoiceBench'te, aşağıdaki gibi metrikler: AlpacaEval, CommonEval ve WildVoice Qwen3-Omni'yi kapalı referans sistemleriyle aynı seviyeye getirin ve sesli muhakemede öne çıkıyor MMAU v05.15.25.
Görsel-işitsel alanda en çok atıf yapılan veri Dünya Duygusu≈54,1Gemini‑2.5‑Flash'ın üstünde; ayrıca şu gibi setlerde de bulunur: DailyOmni y VideoHolmes Thinking varyantı, önceki açık kaynaklı SOTA'lara kıyasla iyileştirmeler sağlıyor. Saf vizyonda, parlıyor MMMU, MathVista, MathVision ve belge anlayışı (AI2D, ChartQA), çok iyi sayılarla sayma (CountBench) ve video anlayışında (Video‑MME, MLVU).
Sıfır atışlı ses üretimi de ölçüldü: CosyVoice ve Seed-TTS gibi ailelerle karşılaştırıldığında, Qwen3-Omni kayıtları daha iyi içerik tutarlılığı birkaç dilde ve yüksek konuşmacı benzerliğiÇok dilli bölümde, “İçerik Tutarlılığı” ve “Konuşmacı Benzerliği” tabloları, Qwen3‑Omni 30B‑A3B'nin Çince ve İngilizce'de oldukça rekabetçi, Almanca, İtalyanca, Portekizce, İspanyolca, Japonca, Korece, Fransızca ve Rusça'da ise sağlam olduğunu göstermektedir. diller arası TTS, CosyVoice 2/3'e kıyasla birden fazla çiftte (örn. zh→en, ja→en, ko→zh) daha iyi WER/tutarlılıklar elde eder.
Mevcut modeller ve her birinin kullanım amacı
Qwen3-Omni serisi, her biri belirli bir kullanım türü için tasarlanmış üç ana parçadan oluşur: Öğretmek, Düşünme y altyazıHepsi aynı çekirdekten geliyor, ancak belirli görevler için etkinleştirilen veya ince ayar yapılan farklı yeteneklere sahipler.
Qwen3‑Omni‑30B‑A3B‑Öğretmek Düşünen ve Konuşan içerir, kabul eder ses, video ve metin ve metin ve ses döndürür. Tam etkileşim ve gerçek zamanlı konuşma sonuçları istiyorsanız, bu tam size göre. demolar için önerilir sesli veya görüntülü.
Qwen3‑Omni‑30B‑A3B‑Düşünme Düşünen'e odaklanıyor zincirleme muhakeme, metinsel çıktıyla birlikte ses, video ve metni destekler. Derinlemesine analiz, karmaşık problem çözme, görüntü tabanlı matematik veya iş akışları için kullanışlıdır. ses çıkışına ihtiyacınız yok ama en iyi yapılandırılmış düşünce.
Qwen3‑Omni‑30B‑A3B‑altyazı rafine edilmiş bir türevdir ses altyazısı Yüksek hassasiyet, düşük halüsinasyon. Açık kaynaklı, rastgele sesleri ayrıntılı bir şekilde ele alıyor ve açık kaynak ekosistemindeki tarihsel bir boşluğu kapatıyor: güvenilir ve zengin altyazılar genel ses için.
Gecikme, gerçek zamanlı ve davranışsal kontrol
Sistem, anlık etkileşim için optimize edilmiştir ve rakamlarla Seste ≈211 ms ve ses-görüntüde ≈507 msAkışın yanı sıra, konuşma dönüşlerinde doğallığa ve ses iletiminde istikrara vurgu yapılır; bu da aralarındaki net rolün bir parçasıdır. Düşünen (metin) ve Konuşan (ses).
Saçları bölmek için stili şu şekilde özelleştirebilirsiniz: sistem istemleriVideo sesinin bir sorgu işlevi gördüğü AV senaryolarında, ekip Düşünen Kişinin muhakemesini koruyan ve daha okunaklı ve konuşma tarzında bir metin oluşturan bir sistem istemi öneriyor ve bu da Düşünen Kişinin işini kolaylaştırıyor. Konuşmacı akıcı bir şekilde ses çıkarıyorAyrıca parametrenin tutarlı tutulması da önerilir videoda_ses_kullan çok yönlü bir sohbet boyunca.
Değerlendirmede belirli yönergeler vardır: kurmayın sistem istemi, her karşılaştırmanın ChatML biçimini izleyin ve herhangi bir istem olmadığında varsayılan olarak aşağıdakileri kullanın: Çince ASR (“请将这段中文语音转换为纯文本。”), diğer dil ASR (“uyarlamak Sesi metne dönüştürün.”), S2TT (“Sağlanan metni dinleyin konuşma…”), ve şarkı sözleri (“uyarlamak Şarkı sözleri” …noktalama yok, satırlar satır aralarından ayrılmış”).
Dağıtım, gereksinimler ve araçlar
Tam bir yerel deneyim için ekip şunları öneriyor: Sarılma Yüz Transformatörleri ve gözden geçir yazılım mühendisliğinin aşamaları, ancak dikkatli olun: bir MoE mimarisi olduğundan, çıkarımda HF ile yavaş olabilir; üretim veya düşük gecikme süresi, kullanmanızı tavsiye ediyorlar vLLM veya DashScope API'sive hatta her ikisi için de ortamlar içeren bir Docker görüntüsü bile sağlıyorlar. Transformers kodu zaten birleştirilmiş, ancak PyPI paketi henüz yayınlanmadı ve kaynaktan yüklemeniz gerekiyor.
Ses ve görüntü/videoyu (base64, URL'ler, gömülü giriş) işlemek için yardımcı programlar sağlarlar ve şunları önerirler: FlashAttention 2 Yüklediğinizde GPU belleğini azaltmak için Transformers ile float16 o bfloat16vLLM ile FlashAttn2 dahil edilmiştir ve şu parametreler mevcuttur: komut_başına_sınır_mm (GPU'da belleği önceden ayırır) ve max_num_seqs paralellik için; ayrıca, yükleme tensör_paralel_boyut çoklu GPU çıkarımını mümkün kılar.
Kaynak tasarrufu için yararlı ayrıntılar var: Sese ihtiyacınız yoksa, Konuşmacıyı devre dışı bırak Başlatma işleminden sonra yaklaşık 10 GB VRAM tasarrufu sağlar. Daha hızlı metin sonuçları istiyorsanız, return_audio=Yanlış nesilde. FlashAttn2 ile BF16 için minimum teorik bellek değerleri de sağlanmıştır: örneğin, Instruct 30B‑A3B yaklaşık ~78,9 GB'dir 15 saniyelik video ve 120 saniyede ~144,8 GB; Düşünme sırasıyla ~68,7 GB ve ~131,7 GB'a düşer.
Birini kaldırmak için demo ağı yerel olarak, vLLM ortamını (veya daha yavaş olan Transformers'ı) hazırlamanızı ve buna sahip olmanızı sağlamanızı önerirler. ffmpeg ve kendi betiklerini kullanırlar. GPU'ya hazır Docker görüntüleri "qwenllm/qwen3‑omni" ile birlikte sunarlar NVIDIA Kapsayıcı Araç Takımı, port eşlemesi (örneğin ana bilgisayar 8901 → konteyner 80) ve 0.0.0.0'da hizmet verme göstergesi. Konteynere herhangi bir zamanda yeniden girilebilir veya konteyner kaldırılabilir.
Demolar, API'ler ve ekosistem
Yerel olarak dağıtmak istemiyorsanız, deneyebilirsiniz Hugging Face Spaces ve ModelScope Studio'daki demolarQwen3‑Omni‑Realtime, Instructing, Thinking ve Captioner için deneyimlerle birlikte. Ayrıca şu özellikler de mevcuttur: Qwen Sohbet Gerçek zamanlı yayınla: sadece seçeneği seçin sesli/görüntülü arama arayüzde.
Ölçekte ve düşük gecikmeyle entegrasyon için önerilen yol şudur: DashScope APIEn öngörülebilir performansı sunan . Ayrıca, topluluk aşağıdaki kanallar aracılığıyla koordine edilir: Discord ve WeChatve gerçek yürütme kayıtlarını içeren ve komut istemlerini veya modelleri değiştirerek sonuçları yeniden üretmeye izin veren yemek kitapları yayınlayın.
Yol haritası ve devam eden iyileştirmeler
Ekip şu anda aşağıdaki gibi ek özellikler üzerinde çalışıyor: çok konuşmacılı konuşma tanıma, Videoya uygulanan OCR, görsel-işitsel proaktif öğrenmede iyileştirmeler ve aracı akışları daha zengin. Ayrıca, desteğin de olduğunu belirttiler. Instruct modeli için vLLM'deki ses çıkışı kısa süre içinde gelecek ve bu da arka uçtan gerçek zamanlı dağıtım döngüsünü kapatacak.
SSS: Çalışma zamanı desteği ve niceleme
Bazı kullanıcılar, Qwen3‑Omni'yi "her zamanki şüphelilerle" bile çalıştıramadıklarını ve Hugging Face'deki nicel araştırmacılar; ayrıca, yerel 16 bit format yaklaşık 70 GB'tır; bu da orta düzey bilgisayarlar için karmaşık bir boyuttur. Projenin kendisi, Transformers'ın zaten birleştirilmiş ancak PyPI paketi olmadan, kaynaktan yüklenmesi gereken ve vLLM'nin çıkarım için tercih edilen seçim olduğu, ancak vLLM'deki talimat ses desteğinin kısa vadede serbest bırakılacak.
Nicelemeyle ilgili olarak, Qwen3‑Omni 30B‑A3B için henüz HF tarafından hazırlanmış yer tutucular listelenmemiştir ve doğanın hatırlanması önemlidir. MoE ve çok modlu llama.cpp gibi çalışma zamanlarıyla anında uyumluluğu zorlaştırır. Şimdi denemesi gerekenler için resmi öneri, Kaynaktan Docker + Transformers/vLLM o APIve destek ve gelecekteki PR'ler için depoyu izleyin nicelikler hazır olduklarında.
İyi değerlendirme uygulamaları ve uyarıları
Sayıları yeniden üretmek için, yönergeler ayrıntılı olarak verilmiştir: çoğu kıyaslamada kullanılır Instruct'ta açgözlü kod çözme örnekleme yapılmadan ve parametrelerin düşünülmesi için generation_config.jsonVideo ayrıca şu şekilde ayarlandı: fps=2 değerlendirme aşamasındadır ve kullanıcı isteminin gitmesi gerektiği belirtilmektedir çok modlu verilerden sonra aksi belirtilmediği sürece.
Bir kıyaslamada komut istemi yoksa, varsayılan komut istemleri (Çince/diğer ASR, S2TT, şarkı sözleri) kullanılabilir. Ayrıca, komut istemi ayarlanmamalıdır. sistem istemi Değerlendirme aşamasında olup, sistemler ve uygulamalar arasında sonuçların karşılaştırılabilir olması sağlanır.
Qwen3‑Omni, sınırlı gecikme süresi, geniş çok dilli kapsamı ile gerçek bir çok modlu platform olarak konumlandırılmıştır. ses ve görsel-işitsel alanda en son sonuçları elde etmek Transformers, vLLM ve Docker kullanarak net bir dağıtım yolu. Metin ve görsellerde iyi mantık yürüten, enerjisini kaybetmeyen ve aynı zamanda Videoyu duyun, konuşun ve anlayın, bugün karşılanması zor bir tekliftir.
İçindekiler
- Qwen3-Omni nedir ve neler sunar?
- Temel yetenekler ve yöntemler
- MoE ile Düşünen-Konuşan Mimarlık ve Tasarım
- Performans ve kıyaslamalar: metin, görüntü, ses ve görsel-işitsel
- Mevcut modeller ve her birinin kullanım amacı
- Gecikme, gerçek zamanlı ve davranışsal kontrol
- Dağıtım, gereksinimler ve araçlar
- Demolar, API'ler ve ekosistem
- Yol haritası ve devam eden iyileştirmeler
- SSS: Çalışma zamanı desteği ve niceleme
- İyi değerlendirme uygulamaları ve uyarıları