- La coherencia de caché garantiza que todas las copias de un mismo dato en distintas cachés y en la RAM se mantengan consistentes en sistemas multinúcleo.
- La jerarquía de caché con un último nivel compartido simplifica el control de coherencia y reduce accesos directos a la memoria principal.
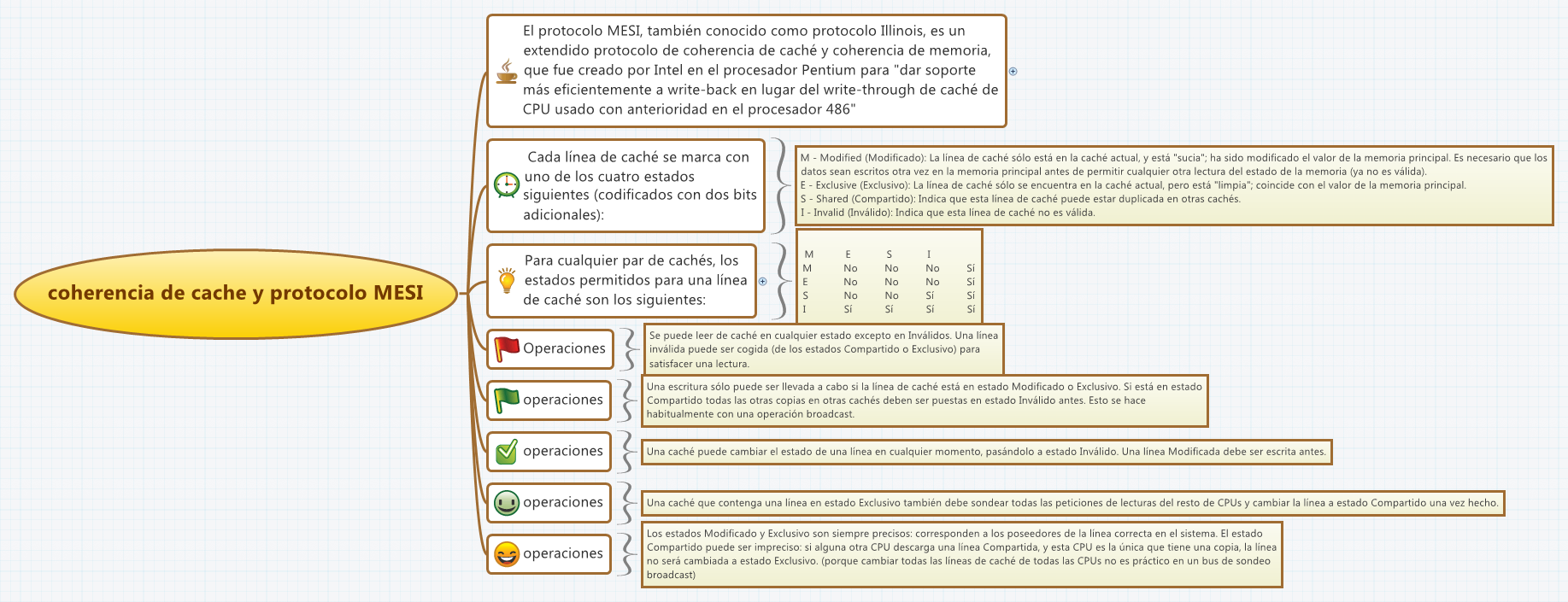
- Los protocolos de coherencia usan estrategias de invalidación o actualización de copias, apoyadas en estados y bits de control por línea de caché.
- El compilador y el sistema operativo pueden complementar la coherencia por hardware insertando instrucciones y configurando memoria para periodos críticos.

Cuando miras un diagrama de cualquier procesador multinúcleo moderno, siempre aparece el mismo patrón: varios núcleos, cada uno con sus propias memorias caché cercanas, y una caché compartida de último nivel que actúa como punto común antes de llegar a la memoria RAM. Esta disposición no es casualidad ni un capricho de los diseñadores, sino una respuesta directa a un problema crítico en sistemas paralelos: la coherencia de caché.
Sin un buen mecanismo de coherencia, cada núcleo podría acabar trabajando con una versión distinta y desactualizada de los mismos datos en memoria, lo que en un programa real equivale a errores sutiles, fallos impredecibles e incluso cuelgues del sistema. Por eso, comprender cómo se mantiene esa coherencia —tanto a nivel de hardware como de software— es clave para entender el rendimiento y la estabilidad de las CPU multinúcleo actuales.
Qué es la coherencia de caché: la metáfora de las terminales

Imagina que varias personas están sentadas delante de diferentes terminales, todas ellas editando el mismo documento almacenado en un servidor central. Cada pantalla muestra una copia del archivo, y se espera que cualquier cambio que haga una persona se vea reflejado inmediatamente en las pantallas del resto.
Para que eso funcione, tiene que existir un mecanismo de sincronización que propague los cambios del documento a todas las terminales, de forma que todas vean siempre la misma versión. Mientras ese sistema funciona, todo va bien: quien modifica el texto sabe que el resto verá la nueva versión casi al instante.
Ahora piensa que ese sistema de sincronización falla de repente. Cada persona sigue editando convencida de que trabaja sobre el documento compartido, pero en realidad cada terminal se ha quedado con su copia local desconectada. A partir de ese momento, los cambios que hace uno no llegan a los demás, y el documento empieza a divergir sin control.
Llevado al terreno de la informática, esto es exactamente lo que pasaría si la CPU no tuviera un protocolo fiable de coherencia: un núcleo modifica un dato en memoria, pero el resto de núcleos continúa leyendo una versión antigua en sus cachés privadas. Eso es terreno abonado para errores lógicos gravísimos, datos corruptos y comportamientos imposibles de depurar.
La coherencia de caché es, por tanto, el conjunto de mecanismos que garantizan que, en un sistema multinúcleo, todas las copias de un mismo dato repartidas por las distintas cachés y la RAM mantengan un estado consistente. Aunque existan múltiples copias, el sistema debe comportarse «como si» solo hubiese una.
Cachés y jerarquía de memoria en una CPU multinúcleo
Las cachés de la CPU son memorias pequeñas y muy rápidas que mantienen copias de fragmentos de la memoria RAM que se utilizan con mayor frecuencia. Cuando el procesador ejecuta código, en lugar de acceder continuamente a la RAM (lenta en comparación), intenta leer y escribir en caché, lo que reduce de forma brutal la latencia.
El truco, claro, es que las cachés no guardan la «versión oficial» de los datos, sino solo una réplica temporal. Siguiendo la metáfora de las terminales, la RAM sería el documento en el servidor, mientras que las cachés serían las pantallas locales que muestran copias de ciertas partes del archivo.
En una CPU multinúcleo, el diseño se complica porque cada núcleo suele tener sus propias cachés privadas de primer nivel (L1) e incluso de segundo nivel (L2). Por encima de estas, se añade una caché compartida de último nivel (L3, por ejemplo), que se sitúa entre los núcleos y el controlador de memoria que da acceso a la RAM.
Esta caché compartida se introduce porque permitir que todos los núcleos accedan de forma directa e intensiva a la RAM provocaría conflictos de acceso, contención en el bus de memoria y un descenso notable del rendimiento. La caché de último nivel actúa como un «amortiguador» común que reduce los accesos a la RAM y centraliza buena parte del tráfico de datos.
Además, muchas arquitecturas organizan las cachés de forma inclusiva: las líneas almacenadas en niveles cercanos al procesador también están presentes en los niveles superiores de la jerarquía. Es decir, una línea que aparece en L1 también está en L2 y, a su vez, en L3. Esto tiene una consecuencia muy útil para la coherencia: basta con actualizar correctamente la caché de último nivel para poder controlar el estado del resto de niveles sin tener que ir constantemente a la RAM.
Por qué la caché compartida de último nivel es clave para la coherencia
Si no existiera esa caché global de último nivel, cada núcleo tendría que comprobar la coherencia directamente contra la memoria principal. Cada vez que se modificara una línea de memoria en una caché privada, sería necesario verificar si otros núcleos mantienen una copia de esa misma línea y, en caso afirmativo, actualizarla o invalidarla en todas partes.
En un sistema con muchos núcleos, esa carga de comprobaciones supondría una cantidad enorme de transacciones hacia la RAM, tirando por tierra gran parte del beneficio de tener cachés rápidas. Al colocar una caché compartida entre los núcleos y la memoria, la CPU puede concentrar el control de coherencia en un solo lugar intermedio.
En muchas implementaciones, las cachés de los niveles superiores (más alejados del procesador) contienen copia de las líneas presentes en los niveles más cercanos al núcleo. Con esta organización, el protocolo de coherencia solo necesita asegurarse de que el último nivel está sincronizado con la memoria principal, y que los niveles privados de cada núcleo estén sincronizados con su nivel inmediatamente superior.
Esto se puede visualizar como una especie de muñeca rusa: la caché de tercer nivel incluye el contenido que está en la de segundo y primer nivel, la de segundo incluye la suya y la del primer nivel, y la de primer nivel solo conoce sus propias líneas. Así, con controlar la «muñeca grande» (el último nivel), el sistema puede coordinar el resto de manera más eficiente.
El resultado es que mantener la coherencia se vuelve más económico en términos de diseño y de tráfico de memoria. En lugar de obligar a cada núcleo a lidiar permanentemente con la RAM, el protocolo actúa sobre la caché compartida y desde ahí gestiona qué líneas deben actualizarse o invalidarse en las cachés privadas.
Métodos de actualización: invalidación y actualización de copias
Un punto delicado aparece cuando dos o más núcleos quieren acceder, casi al mismo tiempo, a la misma línea de datos que está replicada en varias cachés. En ese contexto, los sistemas de coherencia suelen recurrir a dos estrategias fundamentales a la hora de tratar las escrituras.
El primer método se basa en la invalidación. Cuando un núcleo necesita escribir en una determinada línea de caché, el protocolo se encarga de invalidar las copias de esa misma línea que puedan existir en el resto de cachés. Solo el núcleo que va a escribir mantiene la línea en un estado válido para lectura y escritura; el resto, si quiere volver a usar esos datos, tendrán que recargar la línea desde el nivel superior (o desde la memoria) con la versión actualizada.
La segunda estrategia consiste en la actualización. En este caso, cuando un núcleo modifica una línea, el sistema intenta propagar automáticamente el nuevo contenido a las copias existentes en las demás cachés. De este modo, todas las cachés que almacenaban esa línea reciben la versión fresca sin necesidad de invalidarla y recargarla más tarde.
Cada enfoque tiene sus pros y sus contras. La invalidación suele ser más eficiente cuando las escrituras son frecuentes, porque evita saturar el sistema de memoria con actualizaciones que quizá los otros núcleos no necesiten de inmediato. Por el contrario, la actualización puede ser ventajosa cuando muchos núcleos leen a menudo el mismo dato que se modifica de forma relativamente poco frecuente, ya que se reduce la latencia al no tener que recargar la línea tras cada invalidación.
En cualquier caso, detrás de ambos métodos se utilizan estados adicionales y bits de control en las líneas de caché. Es habitual que cada línea incluya información sobre si su contenido coincide o no con el de la RAM, y si está compartida, modificada, exclusiva, reservada, etc., según el protocolo concreto (MESI, MOESI, MSI, etc.). Esto permite que el hardware tome decisiones rápidas sobre qué hacer cuando se produce una lectura o escritura en una línea ya replicada.
Comprobación de coherencia entre cachés y memoria
Comprobar de forma directa la coherencia entre todos los niveles de caché de una CPU o GPU y la memoria principal sería un trabajo mastodóntico, tanto en complejidad de diseño como en coste de rendimiento. Por eso, los sistemas modernos organizan esa verificación de manera jerárquica.
Las cachés más cercanas al procesador (L1, L2) no suelen estar conectadas directamente a la RAM, sino al siguiente nivel de caché. Esto significa que la coherencia no se valida contra la memoria principal en cada nivel, sino respecto al nivel inmediatamente superior. Así se reduce el número de accesos a RAM y se simplifica la lógica necesaria en los niveles inferiores.
Al final, la comparación entre el contenido de caché y el contenido de la RAM se realiza entre la caché de último nivel y la memoria principal. Si este último nivel mantiene un estado correcto y coherente, y cada nivel inferior mantiene su coherencia con el superior, toda la jerarquía se mantiene consistente sin tener que comprobar cada línea frente a la RAM una y otra vez.
Cuando un núcleo escribe en una línea de caché y cambia sus datos, se marca el estado de esa línea para indicar que ya no coincide exactamente con la copia almacenada en memoria. A partir de ahí, el protocolo se encarga de coordinar la actualización: marca las copias correspondientes en otras cachés como reservadas o inválidas y, cuando corresponde, escribe el nuevo contenido en la línea de memoria principal asociada.
Esta organización en forma de cascada permite que los cambios se propaguen progresivamente desde el núcleo que actualiza los datos hasta la memoria principal, pasando por cada nivel de caché de forma controlada. De ese modo, mantener la coherencia no se convierte en un cuello de botella inasumible para el procesador.
Coherencia por hardware frente a coherencia por software
Hasta ahora hemos hablado de mecanismos de coherencia que se implementan principalmente en hardware: protocolos, bits de estado, cachés compartidas, etc. Sin embargo, existe otro enfoque que busca desplazar parte de esa complejidad al software, concretamente al compilador y al sistema operativo.
Los esquemas de coherencia basados en software intentan reducir la necesidad de lógica adicional en el chip, y lo hacen mediante análisis del código y decisiones en tiempo de compilación. La idea es que, si el compilador puede deducir cuándo y cómo se accede a ciertos datos compartidos, podría evitar en muchos casos que esos datos se almacenen en caché o gestionar su visibilidad de forma explícita.
Este enfoque tiene una ventaja clara: una parte de la carga de trabajo pasa de ejecutarse en tiempo de ejecución a resolverse en tiempo de compilación. En lugar de que el hardware detecte y gestione todos los conflictos en caliente, el compilador intenta anticiparlos y generar un código que evite situaciones peligrosas.
La contrapartida es que el análisis estático del código es limitado y, por tanto, los compiladores tienden a ser conservadores. Eso significa que, para no arriesgarse a violar la coherencia, suelen tomar decisiones que reducen la eficacia de las cachés. Si sospechan que unos datos pueden ser problemáticos, es frecuente que impidan su almacenamiento en caché o que fuercen sincronizaciones más frecuentes de lo estrictamente necesario.
Por eso, aunque estos esquemas de software son atractivos en teoría, especialmente para simplificar el diseño del hardware, en la práctica no sustituyen al soporte de coherencia integrado en la propia CPU, sino que lo complementan en algunos escenarios específicos.
El papel del compilador en la coherencia de caché
Un elemento clave de los enfoques de coherencia basados en software es el papel del compilador. El compilador puede realizar un análisis profundo del código y determinar qué estructuras de datos compartidas pueden resultar inseguras para su almacenamiento en caché. Sobre esa base, marca dichos elementos de forma especial o adapta la generación de código.
El enfoque más simple, y también el más conservador, consiste en evitar que las variables de datos compartidas se almacenen en caché. Es decir, cada acceso a esas variables fuerza un acceso a memoria principal o a un área no cacheable. Esto garantiza la consistencia, pero desaprovecha muchas oportunidades de rendimiento, porque una estructura compartida puede, de hecho, usarse de forma privada durante ciertos periodos, o bien de solo lectura en otros.
En realidad, el problema de coherencia solo aparece durante los intervalos en los que al menos un proceso puede escribir en la variable y otro proceso puede leerla. Fuera de esas ventanas críticas, la variable puede tratarse como de uso exclusivo de un hilo o incluso como constante efectiva durante un rato, lo que permitiría cachearla sin problemas.
Las estrategias más avanzadas de compilación intentan justamente identificar esos periodos «seguros» en los que la variable compartida puede considerarse no conflictiva. Para ello, el compilador analiza las rutas de ejecución, los posibles accesos concurrentes y los patrones de sincronización (bloqueos, secciones críticas, etc.). A partir de este análisis, divide el tiempo de vida de la variable en fases: algunas aptas para caché, otras que requieren una gestión especial.
En los periodos críticos, en los que se detecta posible acceso concurrente con escrituras, el compilador inserta instrucciones adicionales en el código generado para hacer cumplir la coherencia de la caché. Estas instrucciones pueden forzar vaciados de caché, recargas desde memoria, barreras de memoria o accesos a regiones marcadas como no cacheables, según el modelo de programación y la arquitectura subyacente.
Relación entre compilador, sistema operativo y hardware
La frase «el compilador inserta instrucciones en el código generado para hacer cumplir la coherencia de la caché» puede llevar a pensar que el sistema operativo lee estas instrucciones como si fueran pistas de alto nivel y, sobre esa base, decidiera cómo ejecutar el programa. En realidad, el mecanismo es algo distinto.
Cuando el compilador añade ese tipo de instrucciones, lo que introduce en el binario son operaciones concretas soportadas por la arquitectura o por el entorno de ejecución. Por ejemplo, puede insertar instrucciones de vaciado de caché, barreras de memoria, instrucciones especiales para marcar regiones como no cacheables o llamadas a servicios del sistema operativo que configuren atributos de memoria.
El sistema operativo no interpreta estas instrucciones como «comentarios» o «hints» de alto nivel escritos por el compilador, sino que simplemente ejecuta el código de máquina como cualquier otro. Lo que ocurre es que parte de esas instrucciones están diseñadas para interactuar con el subsistema de memoria y con la gestión de cachés, de modo que cambian la forma en que la CPU accede a ciertos datos.
En otras palabras, el compilador hace un trabajo previo de análisis y genera código que, al ejecutarse, provoca el comportamiento deseado de la caché. El sistema operativo colabora estableciendo atributos de memoria (zonas cacheables o no, políticas de escritura, etc.) y proporcionando primitivas de sincronización, pero no está «leyendo» instrucciones especiales en el sentido de interpretarlas semánticamente como lo haría un compilador.
También puede ocurrir que el hardware, al ver ciertas instrucciones, active mecanismos específicos de coherencia o de sincronización. Por ejemplo, instrucciones de tipo fence o barrier garantizan el orden de acceso a memoria y fuerzan determinados efectos de visibilidad a través de la jerarquía de caché. En este caso, la colaboración es a tres bandas: el compilador decide dónde colocar esas instrucciones, el sistema operativo configura el entorno de ejecución, y el hardware implementa el comportamiento real a nivel de caché y bus de memoria.
En conjunto, todos estos elementos logran que, aunque existan múltiples copias de los mismos datos repartidas por diferentes cachés y la memoria principal, los programas paralelos se ejecuten con un modelo consistente de memoria. La coherencia de caché, lejos de ser un simple detalle interno de la CPU, se convierte en una pieza central para que los sistemas multinúcleo funcionen de forma fiable y eficiente.
Entender cómo se combinan la jerarquía de caché, los protocolos de coherencia por hardware y las técnicas de apoyo por software deja más claro por qué los diseños de CPU modernas comparten una estructura tan similar, y por qué un pequeño fallo en cualquiera de esos mecanismos puede desencadenar comportamientos caóticos en aplicaciones concurrentes que dependen por completo de que todos los núcleos vean los mismos datos en el momento adecuado.
Tabla de Contenidos
- Qué es la coherencia de caché: la metáfora de las terminales
- Cachés y jerarquía de memoria en una CPU multinúcleo
- Por qué la caché compartida de último nivel es clave para la coherencia
- Métodos de actualización: invalidación y actualización de copias
- Comprobación de coherencia entre cachés y memoria
- Coherencia por hardware frente a coherencia por software
- El papel del compilador en la coherencia de caché
- Relación entre compilador, sistema operativo y hardware