- VibeVoice es un modelo TTS de Microsoft capaz de generar audio largo, expresivo y multialtavoz, ideal para podcasts y audiolibros.
- Su arquitectura combina tokenizadores de habla, un gran modelo de lenguaje y difusión para lograr voces naturales incluso en audios de hasta 90 minutos.
- Permite respuestas casi en tiempo real con variantes ligeras, pero requiere un uso responsable por los riesgos de clonación de voz y deepfakes.
- Ha sido liberado como marco de investigación open source, aunque Microsoft ha limitado temporalmente el repositorio por preocupaciones de uso indebido.
La llegada de VibeVoice de Microsoft está revolucionando la forma de crear podcasts y contenidos de audio largos con inteligencia artificial. Este modelo TTS (texto a voz) de código abierto no solo genera voces hiperrealistas, sino que también permite producir conversaciones con varios interlocutores y duraciones que pueden llegar a los 90 minutos sin cortes raros ni caídas de calidad.
El objetivo de VibeVoice es poner al alcance de cualquiera una “cabina de grabación” virtual capaz de producir podcasts, audiolibros o narraciones de forma profesional desde un ordenador. Basta con tener un guion y algo de conocimiento técnico para desplegar el modelo, y la IA se encarga del resto: entonación, naturalidad, cambios de voz y continuidad a lo largo de todo el audio.
Qué es VibeVoice y por qué es tan importante para los podcasts
El modelo se basa en tecnología TTS (Text to Speech), es decir, transforma directamente texto en voz, pero con un nivel de fluidez y matiz que se acerca mucho al habla humana. VibeVoice se ha liberado inicialmente en versiones de 1.5B y 7B parámetros, pensadas para equilibrar calidad y capacidad de generar audio de gran duración sin un consumo desorbitado de recursos.
Una de sus mayores virtudes es que soporta la creación de audio de hasta 90 minutos de forma continua, manteniendo la coherencia de la voz y la entonación a lo largo de todo el tramo. Esto lo hace especialmente útil para podcasts completos, capítulos de audiolibros o episodios de contenido formativo largos donde antes se necesitaban varias sesiones de grabación con locutores humanos.
Además, VibeVoice está diseñado para manejar hasta 4 voces distintas en un mismo audio, lo que da pie a entrevistas simuladas, mesas redondas, diálogos entre personajes o episodios narrados con diferentes narradores. Esa capacidad multialtavoz es clave para que los podcasts creados con IA resulten más dinámicos y entretenidos.
Cómo funciona VibeVoice: síntesis de voz avanzada y baja latencia
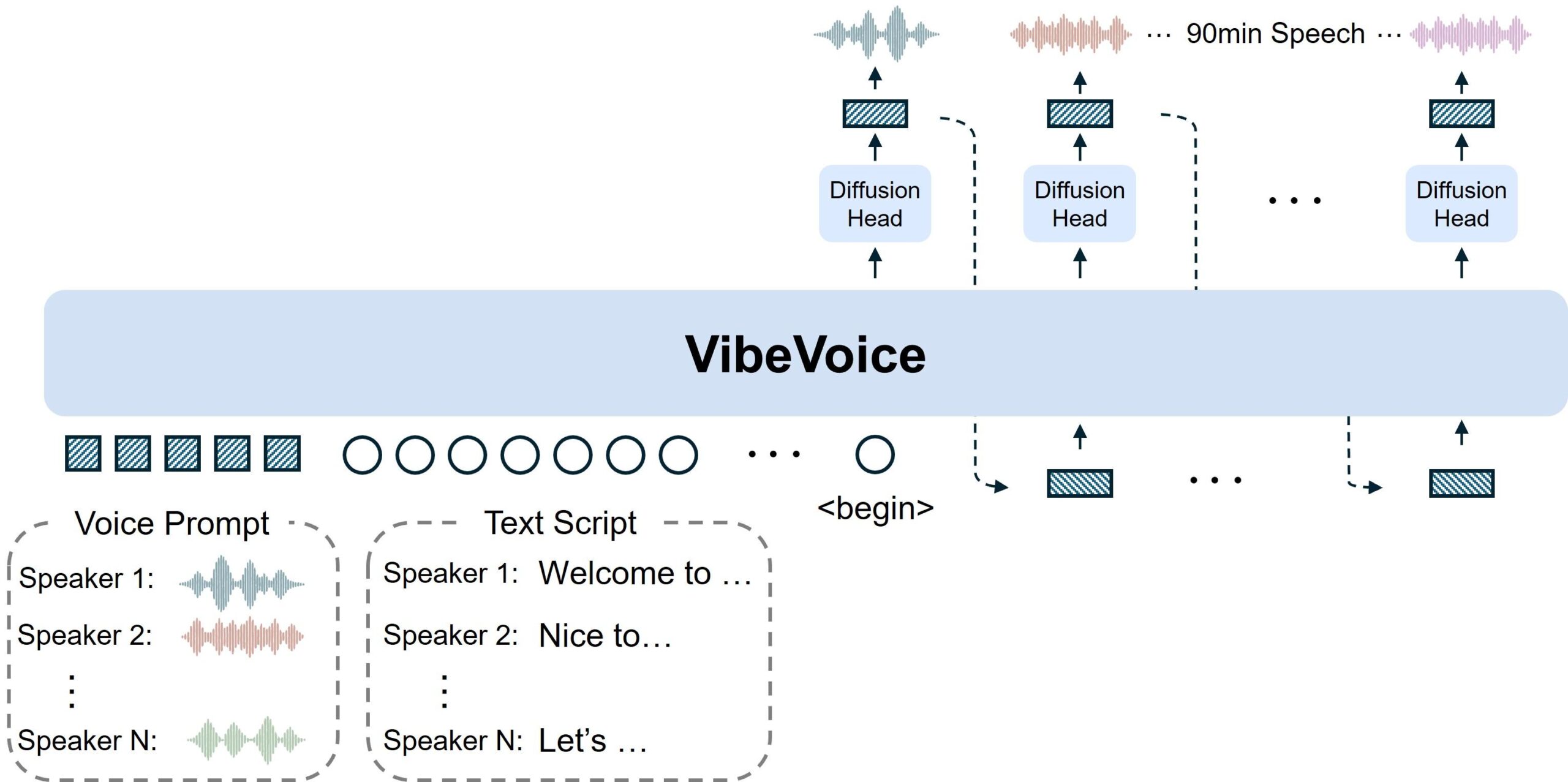
Más allá del titular llamativo, lo que hace especial a VibeVoice es su arquitectura técnica pensada para audio largo y conversaciones. Microsoft combina varios componentes para lograr que la voz suene natural, se adapte al texto y pueda generarse en tiempo real o casi.
El sistema utiliza tokenizadores continuos de habla acústicos y semánticos que funcionan a una frecuencia muy baja, alrededor de 7,5 Hz. Esto quiere decir que condensa la información de audio en menos “pasos” por segundo que otros modelos, conservando la fidelidad sonora pero reduciendo muchísimo el coste computacional al trabajar con secuencias largas.
Sobre esa representación comprimida, entra en juego un modelo de lenguaje grande (LLM) que se encarga de interpretar el contenido del guion, el flujo de la conversación y quién habla en cada momento. Así entiende si se trata de una pregunta, una respuesta, un comentario irónico o un cambio de tema, y adapta la salida de voz a esa intención.
Finalmente, se emplea una cabeza de difusión (diffusion head) que reconstruye los detalles acústicos de alta calidad: timbre, textura de la voz, respiraciones sutiles y otros matices. Esta combinación LLM + difusión permite que el audio resultante sea consistente, expresivo y agradable de escuchar durante muchos minutos seguidos.
En paralelo, Microsoft ha lanzado una variante específica llamada VibeVoice-Realtime-0.5B, pensada para respuestas rapidísimas: este modelo puede empezar a emitir voz en torno a 300 milisegundos después de recibir el texto. Es decir, prácticamente en tiempo real, ideal para agentes de voz, asistentes conversacionales o aplicaciones donde la latencia tiene que ser mínima.
Versiones disponibles: modelos, parámetros y usos recomendados
Dentro del ecosistema VibeVoice se han presentado varias versiones con diferentes tamaños de modelo y orientaciones, pensadas tanto para audio largo como para aplicaciones interactivas.
Por un lado, tenemos las variantes principales de 1.5B y 7B parámetros, diseñadas para gestionar contenidos extensos como podcasts completos, programas de radio simulados, capítulos de audiolibros o cursos en audio. A mayor número de parámetros, más capacidad para capturar matices y gestionar diálogos complejos, aunque también sube la demanda de hardware.
Por otro lado, la versión VibeVoice-Realtime-0.5B prioriza la velocidad de respuesta frente al tamaño del modelo. Aunque cuenta con “solo” 0,5B de parámetros, algo modesto si lo comparamos con gigantes como ChatGPT o Gemini, precisamente eso le permite generar audios de hasta 90 minutos de forma continua manteniendo una voz clara y con entonación estable.
Esta variante en tiempo real es especialmente atractiva para agentes de voz, bots conversacionales, asistentes virtuales y cualquier aplicación donde el usuario espera que la IA responda de inmediato con voz en lugar de solo texto. Con latencias cercanas a los 300 ms, la sensación es muy parecida a hablar con alguien al otro lado.
En todos los casos, el modelo está pensado para usarse desde entornos locales o de investigación, ya que Microsoft decidió liberarlo inicialmente como proyecto de código abierto, accesible desde GitHub y plataformas como Hugging Face, facilitando que la comunidad lo pruebe, lo adapte y construya herramientas encima.
Aplicaciones prácticas: cómo crear un podcast con VibeVoice
Una de las aplicaciones estrella de VibeVoice es, sin duda, la creación de podcasts sin necesidad de locutores humanos. Para cualquier persona que tenga ideas, guiones o contenido escrito, pero no se atreva a ponerse delante del micrófono, este modelo abre una puerta enorme.
El flujo general para producir un podcast con VibeVoice suele pasar por preparar un guion bien estructurado: introducción, bloques de contenido, posibles entrevistas (reales o ficticias), transiciones y cierre. Cuanto más claro esté el texto, mejor podrá el modelo captar cambios de tono, pausas y roles de cada “persona” en la conversación.
Después, mediante las herramientas que se construyen sobre el modelo (scripts, interfaces gráficas o integraciones con otras apps), se asigna cada parte del texto a uno de los altavoces disponibles. Podemos, por ejemplo, usar una voz para el presentador, otra para un invitado recurrente, otra para preguntas leídas de la audiencia y una cuarta para notas informativas o apartados patrocinados.
El modelo se encarga de generar el audio continuo respetando el orden del guion, los cambios entre voces y el ritmo de la conversación. A partir de ahí, es posible pulir el resultado en un editor de audio tradicional, añadiendo música de fondo, efectos de sonido, cortinillas o pequeños ajustes de volumen y ecualización.
Gracias a la capacidad de generar hasta 90 minutos de contenido sin perder coherencia, podemos crear un episodio completo de una sola tirada: no hace falta estar grabando por bloques pequeños ni preocuparse por fatiga de la voz, errores de dicción o ruidos de fondo, algo que en una cabina física es un quebradero de cabeza constante.
AI voice cloning y personalización de voces
Uno de los avances más delicados y a la vez más potentes de esta tecnología es el “voice cloning” o clonación de voz con IA. Se trata de técnicas de síntesis basadas en aprendizaje profundo que permiten replicar el timbre, la forma de hablar y los matices de una voz concreta.
En la práctica, estos sistemas analizan características únicas de la voz objetivo como el timbre, los formantes, el ritmo del habla y los patrones prosódicos (pausas, acentos, entonación de preguntas, etc.). Con solo unos segundos de muestra, son capaces de generar una voz sintética que se parece muchísimo a la original.
En el caso de VibeVoice, se menciona que es posible conseguir simulaciones muy precisas con apenas 10 segundos de audio original, recuperando bastante bien la carga emocional y la textura de la voz. Para un podcast, esto abre escenarios como mantener la “voz de la marca” aunque la persona real ya no grabe, o crear personajes recurrentes con una identidad vocal consistente.
Eso sí, esta capacidad viene acompañada de riesgos éticos muy serios y la necesidad de detección de audio sintético:
Por este motivo, Microsoft subraya que VibeVoice se libera bajo un marco de investigación y con advertencias claras: no debe usarse para suplantación de identidad, fraude, manipulación o campañas de desinformación. El uso responsable es una pieza clave de todo este ecosistema.
Ventajas para creadores de contenido y proyectos pequeños
Con tener un ordenador capaz de ejecutar el modelo y algo de tiempo para escribir guiones, es posible convertir textos largos en audio profesional en cuestión de minutos. Esto se aplica a podcasts informativos, boletines de noticias, historias de ficción, novelas por entregas o incluso manuales técnicos narrados.
También supone una gran ayuda para reciclar contenido escrito existente: artículos de blog, newsletters, hilos de redes sociales o informes se pueden transformar en episodios en audio que amplían el alcance del mensaje y ofrecen una vía más cómoda para quienes prefieren escuchar en lugar de leer.
Otro punto a favor es la coherencia de calidad en el tiempo. Mientras que un locutor humano puede variar su energía, entonación o claridad según el día, la IA mantiene un nivel constante que facilita la producción en serie: varios episodios grabados “del tirón” mantendrán la misma presencia de voz y el mismo estilo.
En el ámbito educativo, VibeVoice encaja de maravilla para cursos en audio, lecturas guiadas y materiales accesibles para personas con dificultades visuales o que simplemente prefieren aprender escuchando mientras hacen otras tareas. La posibilidad de generar versiones habladas de lecciones o documentos extensos da mucho juego.
Riesgos, límites y decisión de Microsoft sobre el repositorio
La otra cara de la moneda es que una IA capaz de imitar voces humanas y generar discursos realistas toca de lleno aspectos éticos y de seguridad. El riesgo de uso malintencionado es real, y las grandes tecnológicas son cada vez más conscientes de ello.
En el propio texto de lanzamiento, Microsoft indica de forma explícita que VibeVoice no debe utilizarse para deepfakes, suplantaciones de identidad ni actividades ilegales. También se menciona de manera directa la prohibición de emplearlo en contextos de desinformación o fraude, precisamente porque su grado de realismo podría engañar fácilmente a oyentes desprevenidos.
Aunque la voz que genera es muy convincente, los responsables del modelo señalan que todavía no alcanza todas las sutilezas de una voz humana real: las respiraciones, las microvariaciones emocionales, ciertas pausas naturales o cambios de ritmo siguen siendo más ricas en una persona que en la IA. Esta “imperfección” puede ayudar, en parte, a detectar que estamos ante una voz sintética, pero la línea se va haciendo cada vez más fina.
Tras la liberación del proyecto como marco de investigación open source, Microsoft detectó casos en los que el modelo se estaba usando de formas que no encajaban con la intención original y sus principios de uso responsable. Como respuesta, la compañía comunicó que se había visto obligada a deshabilitar temporalmente el repositorio hasta asegurarse de que esos usos fuera de alcance no pudieran seguir produciéndose.
En el comunicado se recalca que la responsabilidad en el uso de la IA es un eje central para Microsoft, y que prefieren parar y revisar antes que mantener disponible una herramienta que pueda facilitar abusos graves. Aun así, la documentación, las demos y los materiales técnicos ya han servido para inspirar a la comunidad y seguir avanzando en el campo de la síntesis de voz.
Otras aplicaciones más allá del podcasting
Aunque el foco mediático se ha puesto sobre todo en los podcasts, VibeVoice abre un abanico bastante amplio de casos de uso dentro del mundo del audio generado por IA. Muchos de ellos encajan también en estrategias de contenido digital y automatización.
Uno de los más evidentes son los audiolibros y relatos narrados, donde disponer de voces expresivas, capaces de sostener la atención durante decenas de minutos, es crucial. La capacidad multialtavoz permite que cada personaje tenga su voz, mejorando mucho la experiencia de escucha respecto a un narrador plano.
En el campo de los agentes de voz y asistentes conversacionales, la versión en tiempo real de VibeVoice resulta ideal. Un bot que responde con apenas 300 ms de retraso se siente mucho más natural que uno que tarda varios segundos en hablar, lo que hace que la interacción con servicios de atención al cliente, chatbots o interfaces de voz resulte más fluida.
Otro terreno muy interesante es el del contenido automatizado: resúmenes de noticias, actualizaciones de mercado, reportes periódicos o incluso lecturas de correo y notificaciones pueden generarse sin intervención humana, manteniendo una voz coherente con la imagen de la marca.
Finalmente, hay aplicaciones más experimentales, como la creación de diálogos ficticios, entrevistas simuladas o programas de entretenimiento creados íntegramente por IA. Aquí se mezclan modelos de lenguaje para escribir el guion con VibeVoice para darle voz, dando lugar a formatos que hace poco parecían ciencia ficción.
Mirando todo el conjunto, VibeVoice se sitúa como una pieza clave en la nueva ola de audio generado por IA, capaz de combinar voces naturales, conversaciones con varios participantes, audios muy largos y respuesta casi instantánea. Usado con cabeza y dentro de los límites éticos marcados, puede convertirse en una herramienta potentísima para cualquiera que quiera lanzar o escalar un podcast, producir audiolibros o añadir voz profesional a sus proyectos digitales sin depender siempre de un estudio de grabación tradicional.

Tabla de Contenidos
- Qué es VibeVoice y por qué es tan importante para los podcasts
- Cómo funciona VibeVoice: síntesis de voz avanzada y baja latencia
- Versiones disponibles: modelos, parámetros y usos recomendados
- Aplicaciones prácticas: cómo crear un podcast con VibeVoice
- AI voice cloning y personalización de voces
- Ventajas para creadores de contenido y proyectos pequeños
- Riesgos, límites y decisión de Microsoft sobre el repositorio
- Otras aplicaciones más allá del podcasting