- Los volcados de memoria del kernel capturan el estado del sistema en fallos críticos y son esenciales para depurar y auditar la seguridad.
- En Windows se analizan con WinDbg o KD, usando símbolos y comandos como !analyze -v y .bugcheck para localizar drivers y causas del error.
- En Linux, herramientas como crash, LiME y gcore permiten extraer y estudiar volcados de kernel y procesos, con especial atención a la protección de datos sensibles.
- FreeBSD y otros Unix requieren kernels compilados con símbolos y uso de kgdb, apoyándose siempre en documentación y código fuente para interpretar resultados.
Cuando un sistema operativo entra en pánico o se cuelga a lo bestia, lo único que queda para entender qué ha pasado es el volcado de memoria del kernel y su análisis posterior. Estos volcados capturan el estado interno del sistema en el instante del fallo y son la materia prima para depurar errores complejos, investigar incidentes de seguridad o realizar peritajes forenses.
Aunque pueda sonar muy “bajo nivel”, el análisis de un memory dump no es exclusivo de desarrolladores del núcleo. Administradores de sistemas, ingenieros de soporte e incluso auditores de seguridad pueden sacarle partido si conocen las herramientas adecuadas, los tipos de volcados y las técnicas básicas de interpretación. Vamos a recorrer todo ese camino tanto en Windows como en Unix/Linux y BSD, apoyándonos en herramientas como WinDbg, crash, kgdb o LiME.
Qué es un volcado de memoria del kernel y por qué merece la pena analizarlo
Un volcado de memoria del kernel (a menudo llamado Kernel Crash Dump o simplemente crash dump) es un fichero que contiene una copia, total o parcial, de la memoria en el momento en que el sistema sufre un fallo crítico, como un kernel panic en Unix/Linux o una pantalla azul (BSOD) en Windows.
En la práctica, un volcado de este tipo guarda estructuras internas del kernel, pilas de llamadas, contexto de procesos y drivers cargados. Gracias a esto, después del desastre se puede hacer un análisis “post-mortem” muy parecido a depurar un sistema en vivo, pero sin la presión de tener que tocar una máquina de producción mientras está fallando.
Las razones para meterse a fondo con los volcados del kernel son variadas: desde depurar bugs aparentemente aleatorios y colapsos intermitentes, hasta investigar si un sistema ha sido manipulado de forma maliciosa o si un crash puede haber dejado rastros de información sensible en disco.
Además de los volcados de núcleo completos, existe la posibilidad de sacar volcados de procesos individuales (los clásicos core dumps), que son muy útiles cuando lo que queremos es acotar un problema a una aplicación concreta o revisar el impacto en la confidencialidad de un servicio como un cliente de correo o de mensajería.
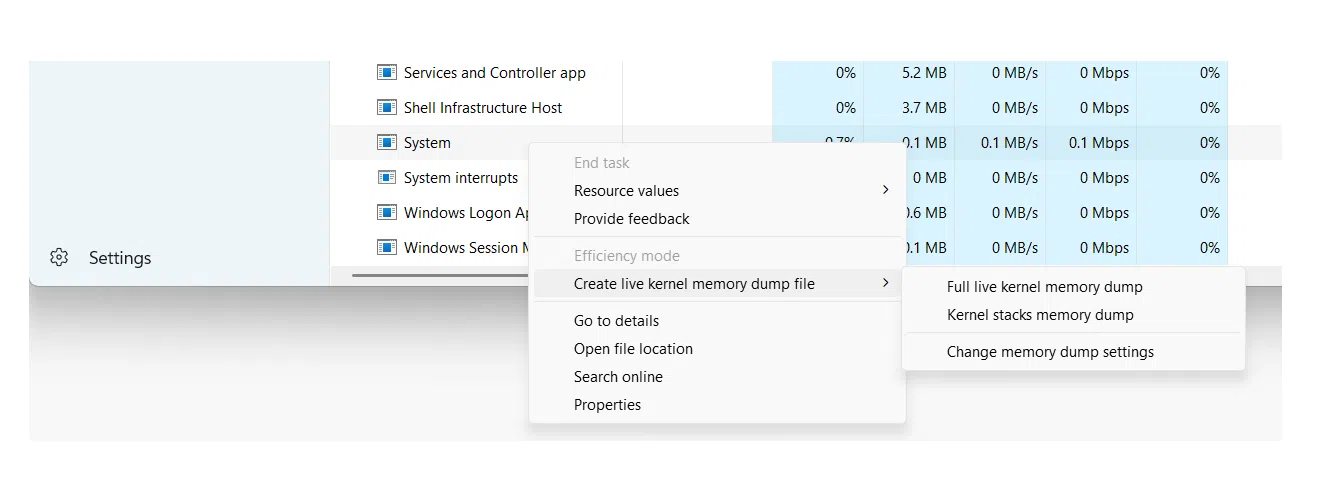
Tipos de volcados de memoria en Windows y su utilidad
En sistemas Windows, el propio sistema operativo es capaz de generar distintos tipos de volcados cuando se produce un STOP error. Cada modalidad incluye un nivel de detalle distinto, por lo que es clave saber qué tipo de volcado necesitamos según el problema y las limitaciones de espacio en disco.
Uno de los formatos más habituales en entornos de usuario y muchos servidores es el volcado de memoria pequeño (small memory dump, minidump). Es el que menos espacio consume y suele situarse en %SystemRoot%\Minidump, con ficheros del estilo MiniMMDDYY-01.dmp.
Este mini volcado contiene información muy concreta pero importante: el código de error STOP y sus parámetros, la lista de controladores cargados en el momento del fallo, el contexto del procesador que se detuvo (PRCB), los contextos del proceso y del hilo implicados (estructuras EPROCESS y ETHREAD) y la pila de llamadas en modo kernel de ese hilo.
Gracias a esas estructuras básicas, incluso con un minidump se puede identificar muchas veces qué driver o módulo está provocando los cuelgues, aunque no siempre será posible seguir toda la pista si el problema se origina lejos del hilo que se estaba ejecutando en el momento del crash y la información de contexto disponible es limitada.
Windows también puede generar volcados de memoria de kernel y volcados completos, mucho más grandes, que contienen porciones o la totalidad de la memoria física. Estos son especialmente útiles en análisis de bajo nivel, investigaciones forenses y debugging avanzado de drivers o del propio sistema.
Configurar y abrir volcados de memoria en Windows con WinDbg y KD
Para aprovechar los volcados en Windows, lo primero es tener bien configuradas las opciones de inicio y recuperación. Desde el Panel de control, en las propiedades avanzadas del sistema, se puede elegir el tipo de volcado que queremos que se genere ante un fallo: por ejemplo, el “Volcado de memoria pequeño (256 KB)” y la ruta donde se almacenará.
El sistema necesita además un archivo de paginación en el volumen de arranque de al menos unos pocos megas para poder escribir el volcado. En versiones modernas de Windows, cada crash crea un nuevo fichero y se mantiene un histórico en la carpeta configurada, lo que permite revisar incidentes pasados con cierta comodidad.
Una vez generados, hay varias maneras de validar que los dumps son correctos. Una utilidad clásica es Dumpchk.exe, que permite comprobar la integridad básica del archivo e imprimir información resumida. Para análisis más avanzados se utilizan las Herramientas de depuración para Windows, que incluyen WinDbg (interfaz gráfica) y KD (versión de línea de comandos).
Tras instalar el paquete de depuración desde la web de Microsoft, lo normal es que las herramientas queden ubicadas en una carpeta como C:\Program Files\Debugging Tools for Windows. Desde ahí podemos abrir un símbolo del sistema y cargar un volcado con WinDbg o KD utilizando el parámetro -z para indicar el fichero:
windbg -y <RutaSimbolos> -i <RutaBinarios> -z <RutaDump>
La ruta de símbolos puede apuntar a un servidor de símbolos con caché local, por ejemplo:
srv*C:\Symbols*https://msdl.microsoft.com/download/symbols
Mientras que la ruta de binarios suele ser algo como C:\Windows\I386 o la carpeta donde tengamos copiados los ejecutables del sistema correspondientes a la versión que generó el dump. Esto es importante porque los minidumps no incluyen todos los binarios, solo referencias a ellos, así que el depurador necesita poder encontrarlos.
Análisis básico de un crash dump de kernel en Windows
Una vez cargado el volcado con WinDbg o KD, el análisis de un crash dump de kernel se parece bastante a una sesión de depuración post-mortem. El primer comando que casi todo el mundo ejecuta es !analyze, que lanza un análisis automático y genera un informe inicial.
El comando !analyze -show muestra el código de comprobación de errores (bugcheck) y sus parámetros, mientras que !analyze -v produce una salida mucho más detallada: módulo sospechoso, pila de llamadas, información contextual y, en muchos casos, sugerencias sobre posibles causas o pasos de diagnóstico.
Para complementar ese análisis, el comando .bugcheck imprime de nuevo el código de error y los parámetros asociados, que se pueden contrastar con la referencia de códigos de bugcheck de Microsoft para conocer el significado exacto de cada valor y las causas típicas.
El comando lm N T (list modules) permite ver el listado de módulos cargados con su ruta, direcciones y estado, lo cual ayuda a confirmar si el driver señalado por el análisis automático está realmente en memoria y qué versión es. Este listado es especialmente útil cuando sospechamos de drivers de terceros o componentes de seguridad que interactúan con el kernel.
Si lo deseamos, podemos simplificar la carga de volcados creando un archivo por lotes que reciba la ruta al dump y lance KD o WinDbg con los parámetros adecuados. Así basta con escribir un comando corto que incluya solo la ubicación del fichero y el script se encarga de todo lo demás.
Uso de WinDbg para volcados de kernel en profundidad
Para volcados de memoria en modo kernel, WinDbg ofrece además la posibilidad de trabajar con múltiples archivos y sesiones. Se pueden abrir dumps desde la línea de comandos con -z, o bien desde la interfaz gráfica, usando el menú Archivo > Abrir volcado de memoria o el atajo de teclado Ctrl+D.
Si WinDbg ya está abierto en modo pasivo, basta con seleccionar el fichero en el cuadro de diálogo “Abrir crash dump”, indicando la ruta o navegando por el disco. Una vez cargado, podemos empezar la sesión con un comando g (Go) en ciertos escenarios, o directamente lanzar los primeros comandos de análisis.
Además del clásico !analyze, conviene familiarizarse con la sección de referencia de comandos del depurador, que describe todas las órdenes disponibles para leer estructuras internas, examinar memoria, interpretar pilas y mucho más. Muchas de estas técnicas son aplicables tanto a sesiones en vivo como a volcados offline.
WinDbg permite también trabajar con múltiples volcados en paralelo. Podemos añadir varios parámetros -z en la línea de comandos, cada uno seguido de un nombre de archivo distinto, o ir sumando nuevos objetivos mediante el comando .opendump. La depuración de varios destinos es útil para comparar fallos recurrentes o incidentes encadenados.
En algunos entornos, los volcados de memoria se empaquetan en archivos CAB para ahorrar espacio o facilitar su envío. WinDbg puede abrir directamente un .cab con un dump dentro, tanto mediante -z como con .opendump, aunque leerá solo uno de los volcados contenidos y no extraerá otros ficheros que pudieran ir en el mismo paquete.
Crash dumps en Unix y Linux: utilidad, herramientas y requisitos
En sistemas Unix y GNU/Linux, la filosofía es parecida pero el ecosistema de herramientas cambia bastante. La mayoría de kernels tipo Unix ofrecen la posibilidad de guardar una copia de la memoria cuando se produce un evento catastrófico, lo que conocemos como core dump o Kernel Crash Dump.
Aunque el uso principal sigue siendo el desarrollo del kernel y de drivers, estos volcados tienen una clara vertiente de seguridad. Un crash puede estar provocado por errores de programación, pero también por acciones maliciosas fallidas, intentos de manipular componentes del sistema o condiciones de carrera explotadas de forma torpe.
En un sistema Unix bien configurado no es habitual tener colapsos diarios, pero cuando ocurren, conviene tener preparada una infraestructura de volcado como Kdump, LKCD u otras soluciones que permitan capturar la memoria del sistema. Eso sí, hay que valorar tanto el valor diagnóstico del volcado como el riesgo de que contenga datos muy sensibles.
Una de las herramientas más completas y extendidas para este tipo de análisis en Linux es crash, inicialmente impulsada por Red Hat. Esta utilidad se ha convertido prácticamente en un estándar de facto para examinar volcados de kernel y también para analizar sistemas en ejecución.
Crash puede trabajar contra la memoria viva del sistema a través de /dev/mem o, en distribuciones Red Hat y derivadas, mediante el dispositivo específico /dev/crash. Aun así, lo habitual es alimentar a la herramienta con un fichero de volcado generado por mecanismos como Kdump, makedumpfile, Diskdump o volcados específicos de arquitecturas como s390/s390x o xendump en entornos virtualizados.
El papel de crash y la importancia de vmlinux en Linux
La utilidad crash nació, en parte, para superar las limitaciones de usar gdb directamente sobre /proc/kcore. Entre otras cosas, el acceso a esa pseudoimagen de memoria puede estar restringido y, además, ciertas opciones de compilación del kernel dificultan interpretar adecuadamente las estructuras internas si solo tenemos el binario ejecutable comprimido.
Para que crash funcione correctamente son necesarios dos elementos clave: un fichero vmlinux compilado con símbolos de depuración (habitualmente con banderas como -g) y el propio volcado del kernel. Esta combinación permite a la herramienta mapear direcciones de memoria a funciones, estructuras y líneas de código.
Es importante distinguir entre vmlinux y vmlinuz. En la mayoría de sistemas solo se ve vmlinuz, que es una versión comprimida y lista para arrancar del kernel. Crash necesita el vmlinux descomprimido con símbolos; sin él, al intentar cargar un dump o /dev/mem nos encontraremos con errores del tipo cannot find booted kernel — please enter namelist argument.
Aunque existe la posibilidad de descomprimir manualmente vmlinuz, el proceso no siempre es trivial y, en la práctica, suele ser mucho más cómodo recompilar el kernel para obtener tanto vmlinux como vmlinuz en paralelo. En entornos de administración seria, es buena práctica conservar el vmlinux correspondiente a cada versión de kernel desplegado precisamente para estos casos.
Una vez reunidos los requisitos, lanzar crash contra un dump es relativamente sencillo: se le indica el vmlinux adecuado y el fichero de volcado, y la herramienta nos abre una sesión interactiva desde la cual podemos recorrer estructuras del kernel, listar procesos, ver pilas de llamadas y extraer información forense. Quien quiera profundizar aún más puede consultar la documentación especializada, como el conocido whitepaper técnico de crash.
Limitaciones de /dev/mem y primeras aproximaciones en Linux
Antes de recurrir a herramientas específicas, muchos administradores han probado históricamente a obtener un volcado de memoria leyendo directamente el dispositivo /dev/mem. Esta aproximación parecía sencilla: usar una herramienta como memdump (que vuelca ese dispositivo a STDOUT) o tirar de dd if=/dev/mem of=volcado.mem.
Sin embargo, en kernels modernos existen opciones de compilación como CONFIG_STRICT_DEVMEM, que limitan severamente el acceso desde espacio de usuario a /dev/mem. El resultado típico es que la lectura se corta tras un pequeño bloque (por ejemplo, 1 MB) o, en el peor de los casos, un bug en esa interacción puede acabar en un kernel panic inmediato y reinicio de la máquina.
Esta protección tiene todo el sentido del mundo desde el punto de vista de seguridad, pero nos obliga a buscar otros caminos para obtener un dump fiable y completo sin fiarlo todo a dispositivos de carácter genéricos que ya no son tan accesibles como antes.
De ahí que la tendencia actual sea apoyarse en módulos específicos o infraestructuras de crash dump integradas, en lugar de intentar “rascar memoria” sin más con herramientas de espacio de usuario que no están pensadas para convivir con las políticas de protección modernas del kernel.
LiME Forensics: extracción de memoria en Linux y Android
Una alternativa muy potente en el mundo forense es LiME (Linux Memory Extractor), un módulo de kernel diseñado precisamente para capturar la memoria volátil de forma controlada y sin las restricciones que afectan a /dev/mem. LiME se ejecuta en espacio de kernel, por lo que puede acceder a la RAM de manera mucho más directa.
LiME se distribuye con su código fuente y se compila frente a los headers del kernel en uso. El proceso de compilación genera un módulo .ko específico para la versión del kernel en el que va a cargarse. Una vez compilado, podemos verificarlo con herramientas como file para asegurarnos de que se ha generado correctamente el módulo ELF correspondiente a nuestra arquitectura.
Para utilizar LiME, basta con cargar el módulo con insmod desde root y pasarle las opciones adecuadas, por ejemplo indicando un destino de volcado por red usando TCP y un formato raw:
insmod lime-3.x.y.ko "path=tcp:4444 format=raw"
En paralelo, en la máquina que recibirá el volcado, escuchamos por el puerto configurado con una herramienta como nc, redirigiendo la salida a un archivo:
nc <IP_origen> 4444 > volcado.mem
Tras unos minutos, según la cantidad de RAM y el rendimiento de la red, tendremos un fichero cuyo tamaño coincide con la memoria física del sistema origen. Se trata de un dump de RAM completo que podremos analizar con herramientas forenses o incluso con strings u otros utilitarios como primera pasada para localizar cadenas interesantes.
Volcados de procesos y riesgos de exposición de datos
Un kernel dump completo es extremadamente informativo, pero también puede ser excesivo cuando lo que nos interesa es un proceso concreto. En ese caso, tiene mucho sentido recurrir a volcados de procesos individuales usando herramientas como gcore en Unix/Linux.
Estos volcados per-proceso son mucho más pequeños y manejables, y permiten centrar el análisis en aplicaciones específicas como un cliente de mensajería (por ejemplo, Skype) o un cliente de correo (como Thunderbird), donde es relativamente sencillo encontrar contraseñas en texto claro, tokens de sesión o datos de contactos si se exploran las cadenas de memoria.
Desde el punto de vista del desarrollo, estos core dumps ayudan a localizar fallos de programación, fugas de memoria o estados inconsistentes en un servicio. Pero, desde la óptica de seguridad, el problema viene cuando los volcados se generan de forma rutinaria y se almacenan en ubicaciones accesibles a otros usuarios, ya sea en el propio sistema o en recursos compartidos de red.
Si un usuario programa, por ejemplo, una tarea cron que captura periódicamente volcados de procesos sensibles y los deja en un directorio de lectura global, está abriendo una puerta enorme a la exposición de información crítica. En muchos escenarios de auditoría, analizar estos ficheros permite a un atacante recuperar credenciales, listas de contactos, historiales de comunicación y otros datos privados con un esfuerzo relativamente bajo.
Por todo ello, en cualquier auditoría seria de un sistema Unix conviene dedicar unos minutos a comprobar si se están generando volcados (totales o parciales), dónde se guardan, qué permisos tienen y si existe algún proceso automatizado que esté dejando copias de memoria al alcance de usuarios no autorizados.
Análisis post-mortem de volcados en FreeBSD con kgdb
En el mundo BSD, y concretamente en FreeBSD, la aproximación al análisis post-mortem pasa por habilitar los crash dumps en el sistema y disponer de un kernel compilado con símbolos de depuración. Esto se controla desde el directorio de configuración del kernel, normalmente en /usr/src/sys/<arq>/conf.
En el fichero de configuración correspondiente se puede activar la generación de símbolos con una línea como:
makeoptions DEBUG=-g # Build kernel with gdb(1) debug symbols
Tras modificar la configuración, hay que recompilar el kernel. Algunos objetos se regenerarán (como trap.o) debido al cambio en los ficheros de construcción. El objetivo es obtener un kernel con el mismo código que el que presenta problemas, pero añadiendo la información de depuración necesaria. Conviene comparar los tamaños antiguo y nuevo con el comando size para asegurarse de que no ha habido cambios inesperados en el binario.
Una vez instalado el kernel con símbolos, ya podemos examinar los dumps con kgdb tal y como se describe en la documentación oficial. Es posible que no todos los símbolos estén completos, y algunas funciones aparezcan sin números de línea o sin información de argumentos, pero en la mayoría de los casos el nivel de detalle es suficiente para seguir la traza del problema.
No hay garantía absoluta de que el análisis vaya a resolver todos los incidentes, pero, en la práctica, esta estrategia funciona bastante bien en un alto porcentaje de escenarios, especialmente cuando se combinan los crash dumps con una buena revisión de cambios recientes en el sistema.
Buenas prácticas de análisis y documentación de errores de kernel
Sea cual sea el sistema operativo, el análisis de volcados de kernel suele terminar remitiendo a documentación técnica, bases de conocimiento, foros especializados o incluso al propio código fuente del kernel para interpretar mensajes, códigos de error y símbolos poco conocidos.
En Linux, resulta muy útil apoyarse en el árbol de código fuente oficial, la documentación integrada y recursos comunitarios. Muchos mensajes de error del kernel se pueden rastrear hasta el fichero exacto donde se generan, lo que ayuda a entender el contexto en el que se dispara un BUG() o un WARN() determinado.
En Windows, la documentación de Microsoft, su base de conocimiento (KB) y los foros técnicos proporcionan explicaciones detalladas de códigos de bugcheck, recomendaciones de resolución y patrones de errores conocidos. Combinando esa información con los informes de !analyze -v es posible trazar un plan de mitigación razonable.
El valor real de un crash dump aparece cuando se cruza toda esa información con conocimientos sólidos del sistema operativo y del entorno concreto donde ha ocurrido el fallo. Solo así se pueden plantear soluciones duraderas y, sobre todo, evitar que el mismo problema se repita en el futuro con consecuencias más graves.
El análisis de volcados de memoria del kernel es, al final, una mezcla de ciencia y artesanía: exige herramientas adecuadas, configuración previa (símbolos, opciones de volcado, almacenamiento seguro) y una buena dosis de experiencia leyendo pilas, estructuras y códigos de error. Dominar estas técnicas permite no solo depurar incidentes complejos, sino también elevar drásticamente el nivel de seguridad y resiliencia de los sistemas que administramos.
Tabla de Contenidos
- Qué es un volcado de memoria del kernel y por qué merece la pena analizarlo
- Tipos de volcados de memoria en Windows y su utilidad
- Configurar y abrir volcados de memoria en Windows con WinDbg y KD
- Análisis básico de un crash dump de kernel en Windows
- Uso de WinDbg para volcados de kernel en profundidad
- Crash dumps en Unix y Linux: utilidad, herramientas y requisitos
- El papel de crash y la importancia de vmlinux en Linux
- Limitaciones de /dev/mem y primeras aproximaciones en Linux
- LiME Forensics: extracción de memoria en Linux y Android
- Volcados de procesos y riesgos de exposición de datos
- Análisis post-mortem de volcados en FreeBSD con kgdb
- Buenas prácticas de análisis y documentación de errores de kernel