- Modelo omnimodal nativo con texto, imagen, audio y vídeo, y streaming en tiempo real.
- SOTA en 22/36 benchmarks de audio/vídeo y multilingüe (119/19/10 idiomas).
- Arquitectura Thinker–Talker con MoE, baja latencia y control por system prompts.
- Despliegue recomendado con vLLM/Transformers, Docker y utilidades oficiales.
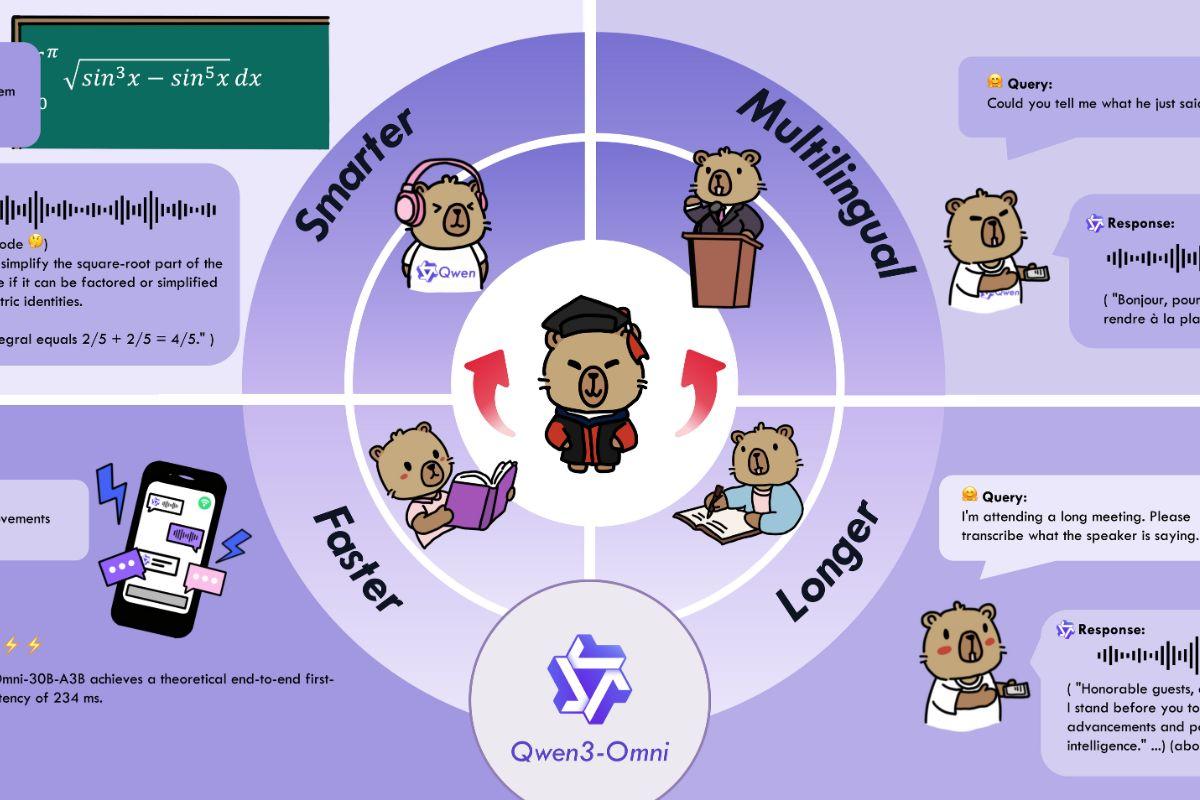
La llegada de Qwen3-Omni ha movido ficha en el tablero de la IA: un único modelo nativo capaz de entender y responder en texto, imagen, audio y vídeo, con respuestas al vuelo tanto escritas como habladas. No hablamos de “parches” multimodales, sino de una arquitectura pensada de base para integrar modalidades con baja latencia y control fino del comportamiento.
En un momento en el que casi todo el mundo prueba chatbots y asistentes, Qwen3-Omni llega con ambición: soporta 119 idiomas por texto, reconoce voz en 19 y habla en 10, entiende audio largo (hasta 30 minutos) y presume de mediciones de referencia en decenas de benchmarks. Además, su diseño Thinker–Talker y un enfoque Mixture of Experts apuntan a velocidad de respuesta y calidad de razonamiento en escenarios reales.

Qué es Qwen3‑Omni y qué aporta
Qwen3‑Omni es una familia de modelos fundacionales “omnimodales” y multilingües de extremo a extremo, diseñados para procesar texto, imágenes, audio y vídeo con salida tanto en texto como en voz natural. La clave no es solo la variedad de entradas y salidas, sino su funcionamiento en streaming con turnos de conversación fluidos y la capacidad de contestar de inmediato.
El equipo ha introducido varias mejoras arquitectónicas para performance y eficiencia: preentrenamiento temprano “texto‑primero” combinado con entrenamiento multimodal mixto, y un diseño con MoE (Mixture of Experts) que mantiene el tipo en texto e imagen mientras impulsa audio y audiovisual. Con ello, el modelo alcanza SOTA en 22 de 36 benchmarks de audio/vídeo y SOTA open‑source en 32 de 36, con resultados comparables a Gemini 2.5 Pro en ASR, comprensión de audio y conversación por voz.
Capacidades clave y modalidades
Qwen3‑Omni llega preparado para casos reales de audio, visión y audiovisual, con soporte multilingüe amplio: 119 idiomas en texto, 19 idiomas de entrada de voz y 10 idiomas de salida de voz. Entre las lenguas de entrada de voz se incluyen inglés, chino, coreano, japonés, alemán, ruso, italiano, francés, español, portugués, malayo, holandés, indonesio, turco, vietnamita, cantonés, árabe y urdu; y en salida, entre otras, inglés, chino, francés, alemán, ruso, italiano, español, portugués, japonés y coreano.
La suite de “cookbooks” oficiales ilustra la amplitud de usos. En audio, se muestra reconocimiento de voz (ASR) multilingüe y de audio largo, traducción voz‑a‑texto y voz‑a‑voz, análisis de música (estilo, ritmo, géneros), descripción de efectos sonoros y captioning de cualquier audio. También admite análisis mixto de pistas con voz, música y ambiente.
En visión hay OCR “duro” para imágenes complejas, detección y grounding de objetos, QA sobre imágenes, resolución de matemáticas en imagen (donde brilla el modelo de Thinking), descripción de vídeo, navegación basada en vídeo en primera persona y análisis de transiciones de escena. En escenarios audiovisuales, demuestra QA audio‑vídeo con alineamiento temporal, interacción guiada con entradas AV y diálogos con comportamiento de asistente.
Como agente, destaca la capacidad de function calling a partir de audio, lo que abre workflows de voz que activan herramientas, y en tareas derivadas existe un Omni‑Captioner para subtitular con gran detalle, que evidencia la capacidad de generalización del fundacional.
Arquitectura Thinker–Talker y diseño con MoE
Una de las ideas diferenciales es separar responsabilidades: el Thinker genera el texto (con variantes con razonamiento explícito tipo chain‑of‑thought), y el Talker produce audio en tiempo real. Este desacoplamiento permite mantener una conversación natural con voz mientras el sistema conserva un alto nivel de comprensión y planificación en texto.
La base MoE reparte la carga entre expertos y se apoya en un preentrenamiento AuT para representaciones generales potentes. Además, el uso de una codificación multicódigo en el canal de audio reduce la latencia al mínimo, algo clave para llamadas o asistentes donde cada centésima de segundo cuenta.
Rendimiento y benchmarks: texto, visión, audio y audiovisual
Qwen3‑Omni mantiene prestaciones punteras en texto e imagen sin degradar respecto a modelos Qwen del mismo tamaño enfocados en un solo modo, mientras que en audio y audiovisual marca el ritmo en la mayoría de pruebas. En la batería de 36 benchmarks de audio y audiovisual consigue SOTA open‑source en 32 y SOTA total en 22, superando en varios puntos a Gemini 2.5 Pro y GPT‑4o.
Algunos hitos destacados en texto: en AIME25 la variante Flash‑Instruct ronda el 65,9; en ZebraLogic el Instruct llega al 90, y en MultiPL‑E alcanza cifras competitivas frente a GPT‑4o. En tareas de alineamiento como IFEval y WritingBench, los modelos Instruct y Thinking muestran puntuaciones altas y consistentes.
En audio, los resultados en ASR para chino e inglés son excelentes: en WenetSpeech y LibriSpeech reduce la tasa de error de palabra de forma notable, con cifras cercanas al 1,22/2,48 en LibriSpeech clean/other, y en conjuntos como FLEURS (multilingüe) ofrece tasas muy bajas. En VoiceBench, métricas como AlpacaEval, CommonEval y WildVoice sitúan a Qwen3‑Omni a la altura de sistemas cerrados de referencia, y en razonamiento sobre audio destaca en MMAU v05.15.25.
En audiovisual, el dato que más se cita es WorldSense≈54,1, por encima de Gemini‑2.5‑Flash; además, en conjuntos como DailyOmni y VideoHolmes la variante Thinking logra mejoras respecto a previos SOTA open‑source. En visión pura, brilla en MMMU, MathVista, MathVision y comprensión de documentos (AI2D, ChartQA), con muy buenos números en counting (CountBench) y en comprensión de vídeo (Video‑MME, MLVU).
La generación de voz cero‑shot también está medida: frente a familias como CosyVoice y Seed‑TTS, Qwen3‑Omni registra mejor consistencia de contenido en varios idiomas y alta similitud de locutor. En la parte multilingüe, la tabla de “Content Consistency” y “Speaker Similarity” muestra a Qwen3‑Omni 30B‑A3B muy competitivo en chino e inglés, y sólido en alemán, italiano, portugués, español, japonés, coreano, francés y ruso. En cross‑lingual TTS, obtiene mejores WER/consistencias en varios pares (ej., zh→en, ja→en, ko→zh) comparado con CosyVoice 2/3.
Modelos disponibles y para qué sirve cada uno
La línea Qwen3‑Omni incluye tres piezas principales, cada una pensada para un tipo de uso: Instruct, Thinking y Captioner. Todas parten del mismo tronco pero con diferentes capacidades activadas o afinadas para tareas concretas.
Qwen3‑Omni‑30B‑A3B‑Instruct contiene Thinker y Talker, acepta audio, vídeo y texto y devuelve texto y audio. Es el indicado si quieres interacción completa y resultados hablados en tiempo real, y es el que se recomienda para demos con voz o vídeo.
Qwen3‑Omni‑30B‑A3B‑Thinking se centra en el Thinker con razonamiento en cadena, soporta audio, vídeo y texto con salida textual. Es útil para análisis exhaustivo, resolución de problemas complejos, matemáticas en imagen o flujos donde no necesitas salida de voz pero sí el mejor pensamiento estructurado.
Qwen3‑Omni‑30B‑A3B‑Captioner es un derivado afinado en subtitulado de audio de alta precisión y baja alucinación. Está abierto, cubre audios arbitrarios con gran detalle y cierra una brecha histórica en el ecosistema open‑source: captions fiables y ricos para audio generalista.
Latencia, tiempo real y control del comportamiento
El sistema está optimizado para interacción instantánea, con cifras de ≈211 ms en audio y ≈507 ms en audio‑vídeo. Además del streaming, se enfatiza la naturalidad en los turnos de conversación y la estabilidad en la entrega de voz, algo a lo que contribuye el rol claro entre Thinker (texto) y Talker (voz).
Para hilar fino, puedes personalizar el estilo con system prompts. En escenarios AV donde el audio del vídeo hace de consulta, el equipo propone un prompt de sistema que mantiene el razonamiento del Thinker y un texto más legible y conversacional, facilitando que el Talker vocalice de forma fluida. También se sugiere mantener coherente el parámetro use_audio_in_video a lo largo de una conversación multi‑turnos.
En evaluación, hay guías específicas: no establecer system prompt, seguir el formato ChatML de cada benchmark y, cuando no haya prompt, usar los siguientes por defecto: ASR chino (“请将这段中文语音转换为纯文本。”), ASR otros idiomas (“Transcribe the audio into text.”), S2TT (“Listen to the provided <source_language> speech …”), y letras de canciones (“Transcribe the song lyrics” … sin puntuación, líneas separadas por saltos»).
Despliegue, requisitos y herramientas
Para una experiencia completa local, el equipo recomienda Hugging Face Transformers y revisar las fases de la ingeniería de software, pero ojo: al ser arquitectura MoE, puede ir lento con HF en inferencia; para producción o baja latencia, aconsejan usar vLLM o la API DashScope, y hasta proporcionan una imagen Docker que incluye entornos para ambos. El código de Transformers ya está fusionado, pero el paquete PyPI aún no se ha publicado y hay que instalar desde fuente.
Proveen utilidades para manejar audio e imagen/vídeo (base64, URLs, entradas intercaladas), y recomiendan FlashAttention 2 con Transformers para reducir memoria GPU siempre que cargues en float16 o bfloat16. Con vLLM, FlashAttn2 viene incluido, y se detallan parámetros como limit_mm_per_prompt (preasigna memoria en GPU) y max_num_seqs para paralelismo; además, subir tensor_parallel_size permite inferencia multi‑GPU.
Hay detalles útiles para ahorrar recursos: si no necesitas audio, puedes desactivar el Talker tras inicializar, ahorrando ~10 GB de VRAM. Y si quieres resultados de texto más veloces, usa return_audio=False en la generación. También se proporcionan valores teóricos mínimos de memoria para BF16 con FlashAttn2: por ejemplo, el Instruct 30B‑A3B ronda ~78,9 GB con vídeo de 15 s y ~144,8 GB con 120 s; el Thinking baja a ~68,7 GB y ~131,7 GB respectivamente.
Para levantar un demo web local, recomiendan preparar el entorno de vLLM (o Transformers, más lento), asegurar que tienes ffmpeg y usar sus scripts. Ofrecen imágenes Docker “qwenllm/qwen3‑omni” listas para GPU con NVIDIA Container Toolkit, mapeo de puertos (ej. anfitrión 8901 → contenedor 80) y la indicación de servir en 0.0.0.0. Se puede reentrar al contenedor o eliminarlo cuando toque.
Demos, API y ecosistema
Si no quieres desplegar en local, puedes probar demos en Hugging Face Spaces y ModelScope Studio, con experiencias para Qwen3‑Omni‑Realtime, Instruct, Thinking y el Captioner. También está disponible Qwen Chat con streaming en tiempo real: basta con elegir la opción de llamada de voz/vídeo en la interfaz.
Para integrar a escala y con baja latencia, la vía recomendada es la API de DashScope, que ofrece el rendimiento más predecible. Además, la comunidad se coordina por canales como Discord y WeChat, y publican cookbooks con logs reales de ejecución que permiten reproducir resultados cambiando prompts o modelos.
Hoja de ruta y mejoras en curso
El equipo trabaja en funciones adicionales como reconocimiento de voz multihablante, OCR aplicado a vídeo, mejoras en aprendizaje proactivo audiovisual y flujos de agentes más ricos. También han indicado que el soporte de salida de audio en vLLM para el modelo Instruct llegará en breve, lo que cerrará el círculo del despliegue realtime desde ese backend.
Preguntas habituales: soporte en runtimes y quantización
Algún usuario ha comentado que no puede correr Qwen3‑Omni aún con los “sospechosos habituales” y que no ve quants en Hugging Face; además, el formato nativo de 16 bits ronda los 70 GB, un tamaño complicado para equipos modestos. El propio proyecto aclara que Transformers ya está mergeado pero sin paquete PyPI, que hay que instalar desde fuente, y que vLLM es la opción preferente para inferencia, si bien el soporte de audio de Instruct en vLLM se liberará en el corto plazo.
Sobre quantización, no se listan aún placeholders preparados en HF para Qwen3‑Omni 30B‑A3B, y conviene recordar que la naturaleza MoE y multimodal complica la compatibilidad inmediata con runtimes como llama.cpp. Para quien necesite probar ya, la recomendación oficial es usar Docker + Transformers/vLLM desde fuente o la API, y vigilar el repo para los PR de soporte y futuras quants cuando estén listas.
Buenas prácticas de evaluación y prompts
De cara a reproducir los números, se detallan pautas: en la mayoría de benchmarks se usa greedy decoding en Instruct sin muestreo, y para Thinking hay que respetar los parámetros del generation_config.json. También se fija el vídeo a fps=2 en evaluación, y se indica que el prompt de usuario debe ir después de los datos multimodales salvo que el conjunto especifique lo contrario.
Cuando un benchmark no incluye prompt, pueden usarse los propuestos por defecto (ASR chino/otros, S2TT, letras de canciones). Además, no se debe establecer system prompt en evaluación, para que los resultados sean comparables entre sistemas y ejecuciones.
Qwen3‑Omni se posiciona como una plataforma omnimodal real, con latencia contenida, cobertura multilingüe amplia, resultados punteros en audio y audiovisual y una ruta de despliegue clara mediante Transformers, vLLM y Docker. Para quien busque un único modelo que razone bien en texto e imagen sin perder fuelle y que, además, oiga, hable y entienda vídeo, es una propuesta difícil de igualar a día de hoy.
Tabla de Contenidos
- Qué es Qwen3‑Omni y qué aporta
- Capacidades clave y modalidades
- Arquitectura Thinker–Talker y diseño con MoE
- Rendimiento y benchmarks: texto, visión, audio y audiovisual
- Modelos disponibles y para qué sirve cada uno
- Latencia, tiempo real y control del comportamiento
- Despliegue, requisitos y herramientas
- Demos, API y ecosistema
- Hoja de ruta y mejoras en curso
- Preguntas habituales: soporte en runtimes y quantización
- Buenas prácticas de evaluación y prompts