- MCP actúa como estándar unificado para que los modelos de IA interactúen con navegadores, apps de escritorio GNOME y servicios externos.
- Existen servidores MCP listos para producción (Cloudflare, GitHub, Figma, Docker, Stripe, etc.) y otros específicos para Linux (Puppeteer, AT-SPI2).
- Desarrollar y desplegar tu propio servidor MCP en GNOME requiere una arquitectura modular, buenas prácticas de seguridad y pruebas exhaustivas.
- Clientes como Claude Desktop o KoboldCpp pueden compartir el mismo ecosistema de servidores MCP, dando flexibilidad al flujo de trabajo en Linux.
Si trabajas con asistentes de IA avanzados y entornos Linux de escritorio, seguramente ya te has topado con el Protocolo de Contexto de Modelo (MCP) y su integración en GNOME. Cada vez más herramientas, servidores y plataformas lo adoptan para que los modelos puedan hablar con aplicaciones, navegadores, APIs y sistemas de escritorio de forma estándar y segura.
En este artículo vamos a ver con todo lujo de detalles cómo funciona el soporte de servidores MCP en un entorno GNOME sobre Linux: desde la automatización del navegador con Puppeteer y la interacción con aplicaciones nativas vía AT-SPI2, hasta la integración con plataformas como Cloudflare, GitHub, Figma, Docker o Stripe. Además, veremos cómo levantar tus propios servidores MCP, probarlos, desplegarlos y qué papel juegan Windows, ChatGPT, Claude y otras herramientas en este nuevo ecosistema.
Qué es MCP y por qué es tan importante en escritorios GNOME
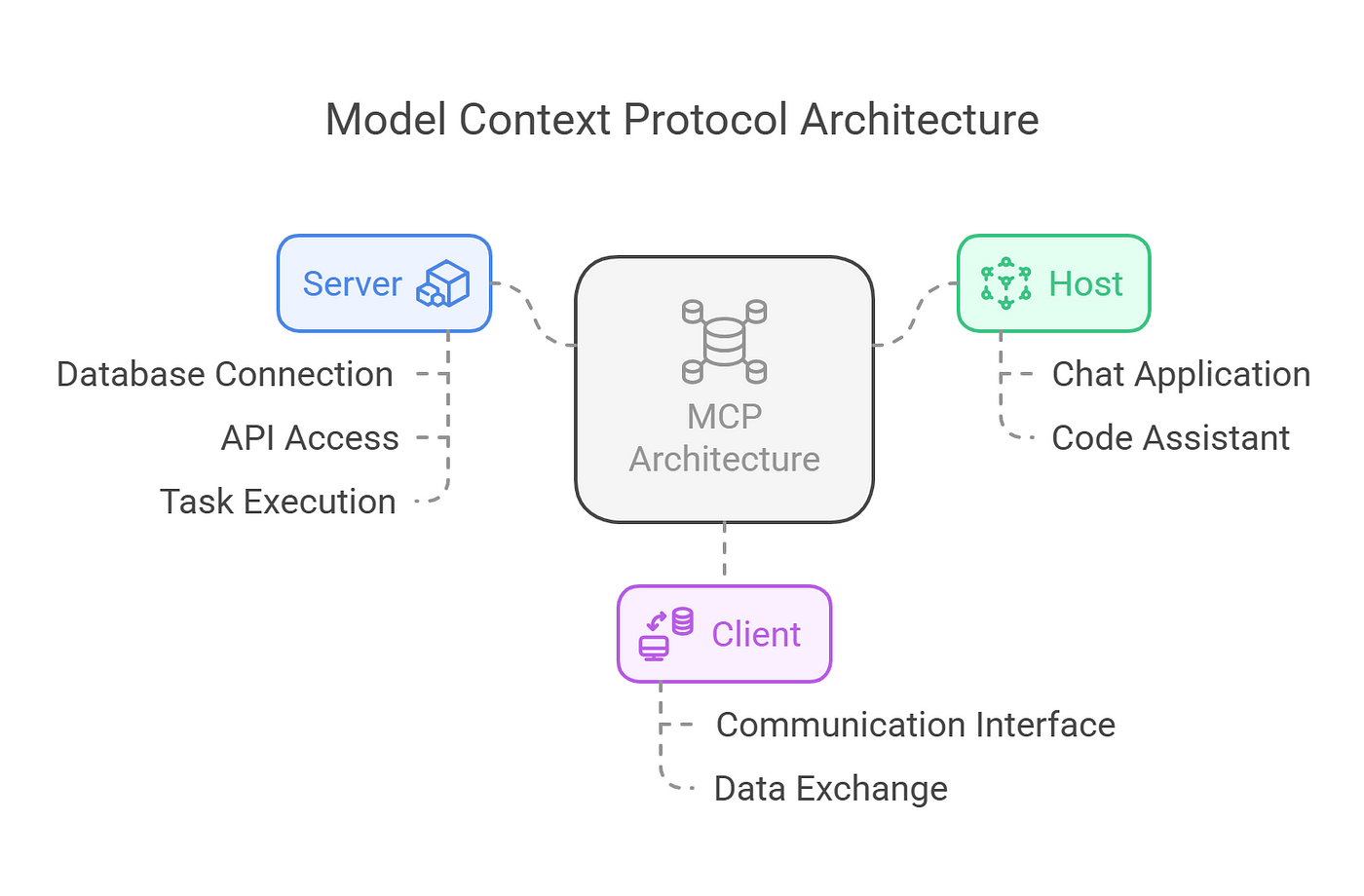
El Protocolo de Contexto de Modelo se ha convertido en algo así como el “USB‑C” de la integración entre modelos de lenguaje y herramientas. En lugar de crear un conector distinto para cada aplicación (CRM, base de datos, panel de despliegue, etc.), MCP define un estándar abierto para que los LLM se entiendan con servidores que exponen herramientas y recursos de forma homogénea.
En la práctica, un servidor MCP es un servicio que ofrece herramientas (acciones) y recursos (datos accesibles) según un esquema bien definido, normalmente usando JSON y JSON Schema. Los modelos de IA pueden descubrir esas herramientas, preguntar qué parámetros aceptan y llamarlas de forma segura, sin que el desarrollador tenga que inventarse un protocolo nuevo para cada caso.
En el contexto de GNOME y otros escritorios Linux, MCP encaja como un guante porque permite que los modelos se conecten a servidores especializados que entienden el ecosistema gráfico: X11, Wayland, accesibilidad AT-SPI2, navegadores controlados por Puppeteer, aplicaciones GTK/Qt/Electron, etc. Todo esto sin forzar a los usuarios a cambiar de entorno ni a depender de integraciones ad hoc.
Desde el punto de vista de arquitectura, MCP separa claramente el cliente (el asistente de IA o la app que lo usa) del servidor (la pieza que habla con el mundo real). Esa separación hace que puedas cambiar el modelo, el IDE o el proveedor cloud sin rehacer todas tus integraciones, siempre que mantengas el mismo servidor MCP y el mismo contrato de herramientas.
Soporte de MCP en Windows, dudas sobre la web y uso en escritorio
Una de las preguntas que más ronda hoy en día a la gente que prueba MCP es hasta qué punto es sencillo hacerlo funcionar en Windows, especialmente con servidores basados en Node.js. Muchos usuarios se han peleado con instalaciones manuales, rutas de Node, configuraciones de seguridad de PowerShell o problemas con el fichero de configuración del cliente de IA.
Para aliviar este dolor de cabeza, alguien decidió pedirle a Claude que generara un script de PowerShell capaz de gestionar la instalación y actualización de servidores MCP. El resultado es un guion (alojado en un gist público) que puedes descargar como mcp-install.ps1. La idea es muy simple: si el paquete aparece en mcp-get.com y se identifica con el icono de Node.js, el script se encarga de descargarlo, instalarlo y dejarlo listo para su uso.
El flujo típico en Windows consiste en abrir PowerShell y ejecutar algo como ./mcp-install.ps1 @modelcontextprotocol/server-everything. Este comando despliega un servidor de ejemplo que sirve para comprobar que toda la tubería MCP funciona correctamente con tu cliente (por ejemplo, Claude Desktop). Las capturas del proceso muestran qué esperar y ayudan a verificar que todo ha quedado bien configurado.
Un detalle interesante es que el script no sobrescribe tu archivo claude_desktop_config.json. En su lugar, comprueba el punto de entrada del paquete MCP y actualiza la configuración de forma incremental. Si el servidor MCP ya está instalado, se limita a actualizarlo, respetando tus ajustes previos. Esto reduce el riesgo de perder configuraciones personalizadas o rutas a otros servidores.
En sistemas Windows con versiones antiguas de PowerShell, es posible que tengas que ejecutar antes Set-ExecutionPolicy Bypass -Scope Process para permitir la ejecución del script. Es una solución habitual cuando PowerShell bloquea la ejecución de archivos .ps1 descargados de Internet por motivos de seguridad.
En paralelo surge otra duda cada vez más frecuente: ¿veremos versiones web de Claude o ChatGPT con soporte completo para MCP? A nivel de arquitectura no hay nada que lo impida: los servidores MCP ya existen, suelen hablar HTTP o STDIO, y el protocolo está bien documentado. Lo que frena a los proveedores suele ser una mezcla de seguridad, permisos, límite de recursos, UX y gobernanza: exponer MCP en la web implica permitir que modelos alojados en la nube hablen con sistemas externos, potencialmente sensibles, desde un navegador.
Mucha gente se imagina un futuro en el que abre su ChatGPT o Claude vía web, con todas sus herramientas MCP personales conectadas (GitHub, Figma, Jira, Docker, etc.), y lanza comandos complejos sin tocar la terminal. Esa visión es técnicamente plausible y, de hecho, algunos pasos ya se están dando, pero requerirá políticas finas de permisos, OAuth bien montado y una UX que explique claramente qué puede hacer la IA en cada momento.
Dentro del ecosistema Linux, uno de los servidores MCP más potentes es el que automatiza un navegador real mediante Puppeteer, con soporte nativo tanto para X11 como para Wayland. Este servidor permite que un modelo de lenguaje interactúe con páginas web como si fuera una persona: abrir URLs, hacer clic en elementos, rellenar formularios, ejecutar JavaScript, capturar pantallazos y leer los logs de la consola.
Esta implementación incluye una capa específica para gestionar el servidor de visualización en Linux (X11, Wayland o incluso XWayland). La bifurcación que se describe en la documentación añade detección automática del entorno gráfico y configura dinámicamente las variables que necesita Puppeteer para levantar el navegador sin problemas, tanto en GNOME como en KDE y otros escritorios.
Entre las capacidades clave de este servidor MCP de navegador destacan la detección automática de X11/Wayland, la configuración dinámica de variables como DISPLAY y XAUTHORITY, el soporte para XWayland como mecanismo de compatibilidad, y una serie de rutinas de fallback con manejo robusto de errores para evitar que el servidor se caiga ante entornos más exóticos.
En cuanto a recursos, este servidor ofrece dos tipos de URI muy útiles: por un lado, los registros de la consola accesibles mediante console://logs, y por otro, las capturas de pantalla referenciadas como screenshot://<name>. Esto proporciona al modelo un contexto visual y de depuración muy valioso cuando está automatizando flujos E2E o inspeccionando aplicaciones web complejas.
Las funciones disponibles permiten cubrir gran parte de las acciones típicas de QA y scraping: navegación entre páginas, clicks, envío de formularios, ejecución de scripts personalizados, lectura de la consola y gestión de capturas. Para quienes trabajan desde GNOME, esta capa MCP abstrae por completo las peculiaridades del servidor de visualización y deja al modelo hablar en un lenguaje de alto nivel.
Soporte MCP para aplicaciones de escritorio Linux vía AT-SPI2
Más allá del navegador, existe otro servidor MCP muy interesante que se encarga de interactuar con aplicaciones de escritorio nativas en Linux a nivel de accesibilidad. Usa AT-SPI2 (Assistive Technology Service Provider Interface), el estándar de accesibilidad en entornos GNOME y otros escritorios modernos, para exponer una especie de “árbol semántico” de la interfaz.
Este servidor ofrece algo parecido a lo que dan algunas extensiones de Chrome con sus referencias tipo ref_1, ref_2, pero aplicado a ventanas GTK, Qt, Electron y cualquier app que publique su información accesible. Es capaz de detectar roles (botones, textos, enlaces, menús, etc.), estados (enfocado, habilitado, marcado, editable) y proporcionar una búsqueda en lenguaje natural de elementos de la interfaz.
Entre sus herramientas más destacadas están funciones como desktop_snapshot, que captura el árbol de accesibilidad con referencias semánticas, desktop_find para localizar elementos a partir de descripciones tipo “botón guardar” o “campo de búsqueda”, desktop_click para hacer clic por referencia o coordenadas, desktop_type para escribir texto, desktop_key para enviar atajos de teclado y desktop_capabilities para consultar qué tipo de automatización está disponible en cada entorno.
En GNOME, para que todo esto funcione correctamente, es imprescindible que la accesibilidad del escritorio esté activada. Normalmente se hace desde Configuración → Accesibilidad. En KDE también hay opciones similares en el panel de Sistema. La mayoría de escritorios modernos lo activan por defecto, pero en algunos casos hay que reiniciar sesión para que el daemon de AT-SPI2 arranque bien.
En cuanto a compatibilidad con plataformas gráficas, este servidor MCP soporta X11, Wayland y XWayland. En una tabla de capacidades se expone que la detección AT-SPI, el clic por referencia, la escritura de texto y el uso de herramientas como ydotool están completamente soportados en los tres entornos, mientras que xdotool funciona a pleno rendimiento en X11 y XWayland, pero no se utiliza en sesiones Wayland puras.
En el apartado de resolución de problemas, la documentación menciona errores típicos como “AT-SPI2 not available” o “AT-SPI2 registry not running”, que suelen deberse a que la accesibilidad no está habilitada o a que el servicio no se ha iniciado correctamente. También se contempla el mensaje “No input backend available” en Wayland, que suele resolverse instalando y configurando las herramientas de simulación de entrada adecuadas. Además, se avisa de que ciertas aplicaciones antiguas o mal integradas pueden no exponer su árbol de accesibilidad, por lo que algunos elementos no aparecerán en los snapshots.
MCP como estándar de integración para equipos frontend
Más allá del escritorio, MCP se está consolidando como la referencia para integrar herramientas críticas del flujo de trabajo frontend: diseño (Figma), control de versiones (GitHub, GitLab), despliegue (Vercel, Netlify, Cloudflare), observabilidad (Sentry, Chromatic) y gestión del trabajo (Linear, Jira, Notion, Atlassian, etc.).
Se habla de MCP como el equivalente a un “USB‑C para integraciones de agentes y herramientas”, porque permite conectar especificaciones de diseño, repositorios, pipelines de despliegue, monitorización y gestión de tareas en un mismo canal que entienden tanto los asistentes de IA como los editores de código y los sistemas CI/CD. Sin capas de adaptadores personalizados para cada pareja de herramientas.
Ya hay un listado bastante completo de servidores MCP remotos listos para producción, muchos de ellos con OAuth y permisos granulares. Por ejemplo, Cloudflare mantiene un catálogo de servidores MCP administrados que se integran con Workers, Pages, KV o R2; Notion ofrece un servidor (oficial o comunitario) para leer y escribir documentos, tareas y especificaciones; GitHub y GitLab cuentan con sus propios servidores MCP para gestionar issues, pull/merge requests y automatizar flujos de revisión de código.
Otras plataformas que se han sumado son plantillas y servidores MCP que controlan despliegues, entornos, dominios y proyectos, o Supabase, que expone acceso de solo lectura a bases de datos y otras capacidades de plataforma pensadas para aplicaciones frontend. En el terreno de la gestión de trabajo, Linear y Atlassian (Jira/Confluence) proporcionan MCP remotos que permiten crear incidencias, actualizar estados, consultar sprints o resumir páginas conociendo los permisos de cada usuario.
En el ámbito de la observabilidad, Sentry ofrece un servidor MCP (con versión alojada y OSS) para consultar errores, traer contexto de problemas en tiempo real y hasta generar parches sugeridos. Stripe facilita la interacción con su API y documentación de pagos; Chromatic/Storybook exponen herramientas para pruebas visuales y revisión de interfaz; y proyectos como Grep MCP permiten hacer búsquedas de código a escala en repos públicos de GitHub, combinando expresiones regulares y semántica.
Todo esto hace que, para un equipo de frontend moderno, MCP sea una opción muy pragmática para 2025 y en adelante. En lugar de mantener scripts pegados con cinta aislante, bastaría con elegir el conjunto adecuado de servidores MCP (Figma, GitHub/GitLab, Vercel/Netlify/Cloudflare, Sentry/Chromatic, etc.) y dejar que el asistente de IA orqueste el flujo de diseño → código → despliegue → monitorización dentro del editor o del sistema CI.
Guía práctica: anatomía y desarrollo de un servidor MCP propio
Si quieres llevar el soporte MCP en GNOME un paso más allá, tarde o temprano te tocará construir tu propio servidor MCP. Más allá de usar los servidores ya hechos, crear uno desde cero te obliga a entender la arquitectura backend, la gestión de herramientas y el modelo de mensajes del protocolo, lo que te da un control absoluto sobre cómo tu IA interactúa con tus sistemas.
La arquitectura típica de un servidor MCP es modular y suele dividirse en cuatro bloques: la aplicación principal de servidor, los módulos de herramientas y recursos, los manejadores de comunicación y los puntos de integración. La aplicación se encarga de abrir sockets o endpoints HTTP/STDIO, gestionar conexiones concurrentes, autenticar clientes y coordinar el flujo de datos.
Los módulos de herramientas son piezas de código que encapsulan acciones concretas: consultar una base de datos, hacer un cálculo, disparar un despliegue, lanzar un playbook de automatización, etc. Cada herramienta tiene un nombre único, una descripción clara, un esquema de parámetros y un esquema de respuesta, muchas veces definido en JSON Schema para asegurar la validación. El servidor mantiene un registro de estas herramientas y, cuando llega un mensaje MCP, reenvía la petición a la función adecuada.
Los manejadores de comunicación se ocupan de parsear los mensajes que llegan en formato MCP, comprobar que cumplen el esquema y encaminar cada solicitud a la herramienta o recurso correspondiente. También se encargan de dar forma a la respuesta, rellenando los campos esperados por el cliente (resultados, errores, metadatos, etc.). Por último, los puntos de integración son las interfaces externas que permiten a asistentes y apps conectarse: endpoints HTTP, WebSockets, transporte STDIO o lo que defina la implementación.
El flujo de interacción es sencillo: un cliente envía una solicitud MCP al servidor, el manejador la interpreta, el servidor ejecuta la herramienta indicada y el manejador empaqueta la respuesta y la devuelve. Gracias a este diseño por capas, puedes sustituir el transporte o añadir nuevas herramientas sin tocar el núcleo lógico de la aplicación.
Para desarrollar un servidor MCP en la práctica, sueles empezar eligiendo un lenguaje de programación con buen soporte de red como Python o Node.js. En Python, frameworks como Flask o FastAPI son habituales; en Node.js, Express encaja muy bien. Es recomendable estructurar el proyecto con carpetas para herramientas (/tools), manejadores (/handlers) y un archivo principal (server.py o server.js), además de los archivos de dependencias (requirements.txt o package.json).
A nivel de entorno, lo más sano es trabajar con entornos virtuales o aislados: venv en Python, o simplemente un proyecto con node_modules en Node.js. El control de versiones con Git y un buen .gitignore ayudan a mantener las cosas limpias. Documentar el proceso de instalación en un README facilita que otros desarrolladores reproduzcan tu servidor MCP en sus máquinas.
Herramientas, recursos, pruebas y despliegue de servidores MCP
Definir bien tus herramientas es clave para que un modelo de lenguaje pueda usarlas de forma fiable. Cada herramienta debería hacer una única cosa claramente definida (principio de atomicidad), con un nombre descriptivo, una explicación clara y un esquema detallado de entrada y salida. Esto hace que el servidor pueda anunciar sus capacidades y que el cliente (el modelo) entienda qué puede pedir y qué va a recibir.
En el código, sueles mantener un registro de herramientas (por ejemplo, un diccionario en Python que mapea nombres de herramienta a funciones). Añadir una nueva herramienta consiste en escribir la función con sus validaciones, documentarla y añadirla a ese registro. Los recursos, por su parte, son los datos o servicios que esas herramientas tocan: bases de datos, APIs externas, sistemas de ficheros, colas, etc.
La fase de pruebas incluye tanto pruebas manuales (con MCP Inspector, Postman o cURL) como test automatizados. Lo habitual es enviar mensajes MCP de ejemplo al endpoint del servidor y verificar que las respuestas cumplen el formato esperado, incluyendo códigos de error, estructura de datos y campos obligatorios. En Python, pytest facilita las pruebas unitarias y de integración; en Node.js, frameworks como mocha o jest cumplen esa función.
Para depurar, es vital tener un sistema de logs bien pensado. Bibliotecas como logging en Python o winston en Node.js te permiten registrar qué está ocurriendo cuando llega una solicitud, qué herramienta se ejecuta, qué parámetros entran y qué sale. En entornos de desarrollo puedes usar depuradores gráficos (VS Code, PyCharm, WebStorm) para poner breakpoints y examinar variables a fondo.
Una vez que tu servidor MCP funciona en local, el siguiente paso es desplegarlo. Muchas personas optan por contenedores Docker y plataformas como Google Cloud Run, AWS ECS o Azure App Service, que ofrecen escalado automático, alta disponibilidad y manejo de certificados TLS integrado. Es importante trasladar toda la configuración sensible (claves de API, credenciales, etc.) a variables de entorno y mantener los secretos fuera del código.
La seguridad se apoya en mecanismos de autenticación como claves de API o OAuth, limitando el acceso solo a clientes de confianza. También conviene definir límites de recursos y políticas de escalado horizontal para que el servidor pueda manejar picos de tráfico. La monitorización con herramientas tipo CloudWatch o Google Operations, y la exposición de endpoints de health check, hacen que detectar incidencias sea mucho más sencillo.
En cuanto al mantenimiento, conviene actualizar regularmente dependencias y sistema operativo, aplicar parches de seguridad y usar estrategias de despliegue blue/green o rolling para evitar caídas de servicio. Todo esto es igual de aplicable a un servidor MCP que automatiza GNOME que a uno que integra Stripe o GitHub.
Servidores MCP para Docker y sandboxes de Linux controlados por IA
Otro ejemplo muy ilustrativo de lo que se puede hacer con MCP es el servidor que usa Docker Engine para crear sandboxes de Linux controladas por la IA. Este tipo de servidor levanta contenedores aislados en los que herramientas como Gemini-cli o Claude pueden ejecutar comandos, compilar código, editar ficheros e incluso abrir editores como vim, mientras el usuario ve todo lo que pasa.
En una demostración típica, el usuario pide a la IA que escriba un programa en C, lo compile y lo ejecute dentro del contenedor, indicándole que use un editor de terminal. El servidor MCP actúa como intermediario: crea el contenedor, expone las herramientas adecuadas, reenvía los comandos y captura las salidas. Todo ello con un alto grado de visibilidad, de modo que sabes exactamente qué está haciendo el modelo dentro del sandbox.
Esta aproximación resulta muy útil para experimentos, formación o tareas de desarrollo potencialmente peligrosas, ya que mantiene el sistema anfitrión a salvo. El código fuente de este servidor concreto está disponible en GitHub, lo que te permite estudiarlo, adaptarlo a tu caso o contribuir con mejoras. Es un ejemplo perfecto de cómo MCP puede conectar IA y contenedores de manera extremadamente flexible.
En entornos GNOME, esta clase de servidor tiene mucho sentido: puedes usar un cliente MCP de escritorio, pedirle a la IA que monte un entorno de pruebas en Docker, y seguir trabajando en tus aplicaciones gráficas mientras el contenedor hace su trabajo en segundo plano. La separación entre escritorio y sandbox te da tranquilidad sin renunciar a la potencia de la automatización.
Además, combinar este tipo de servidor con los de automatización de navegador o escritorio (vía Puppeteer o AT-SPI2) abre la puerta a flujos de trabajo muy avanzados: por ejemplo, levantar una app en Docker, lanzar un navegador controlado por MCP para hacer tests E2E, y al mismo tiempo dejar que el modelo interactúe con diálogos y ventanas del escritorio.
MCP en clientes alternativos: ejemplo de KoboldCpp
No todo el soporte MCP se limita a clientes comerciales como Claude Desktop. Herramientas como KoboldCpp han incorporado soporte nativo para MCP en versiones recientes, con la idea de ofrecer una alternativa de escritorio capaz de conectarse a los mismos servidores que usarías con otros clientes.
En la versión 1.106 de KoboldCpp, se ha añadido un “puente MCP” que puede conectarse a todos los servidores declarados en un archivo mcp.json con el mismo formato que usa Claude Desktop. Este puente es capaz de hablar tanto con servidores MCP basados en HTTP como con los que utilizan STDIO como transporte, reenviando automáticamente las llamadas a herramientas que la IA decida lanzar hacia el servidor correcto.
Desde la interfaz de usuario de KoboldCpp puedes consultar la lista de herramientas disponibles en todos los servidores MCP conectados, activar o desactivar las que quieras que el modelo pueda usar e incluso habilitar un sistema de aprobaciones para las llamadas de herramienta, de forma que tengas que confirmar antes de que la IA ejecute ciertas acciones sensibles.
Esto demuestra que MCP no está ligado a un único proveedor, sino que cualquier cliente que implemente el protocolo puede aprovechar el mismo ecosistema de servidores. En la práctica, si tienes un conjunto de servidores MCP ya configurados para tu entorno GNOME, puedes probar distintos clientes (Claude, KoboldCpp, editores con plugins MCP, etc.) sin rehacer todas las integraciones.
La comunidad alrededor de KoboldCpp ha compartido capturas donde se ven varios servidores de herramientas en acción al mismo tiempo, mostrando cómo el puente MCP coordina distintas capacidades sin que el usuario tenga que tocar apenas la configuración una vez definido el mcp.json.
Al final, este tipo de avances refuerza la idea de MCP como estándar transversal para agentes y herramientas, no como un añadido propietario de un producto concreto. Eso beneficia tanto a quienes usan GNOME y Linux como a los que están en Windows o macOS.
Con todo lo anterior, el panorama para el soporte de servidores MCP en entornos GNOME es muy prometedor: disponemos de automatización de navegador y escritorio con soporte X11/Wayland, servidores remotos para prácticamente todas las herramientas clave de un equipo de desarrollo moderno, guías detalladas para construir y desplegar servidores propios y clientes cada vez más diversos que entienden el protocolo. Si se combina esto con buenas prácticas de seguridad, accesibilidad activada en el escritorio y una estrategia clara de qué servidores habilitar, es posible montar un flujo de trabajo en el que la IA deje de ser un simple chatbot y se convierta en un operador capaz de moverse con soltura entre tus aplicaciones GNOME, tus contenedores Docker y tus plataformas cloud.

Tabla de Contenidos
- Qué es MCP y por qué es tan importante en escritorios GNOME
- Soporte de MCP en Windows, dudas sobre la web y uso en escritorio
- Automatización de navegador con Puppeteer y soporte de X11/Wayland
- Soporte MCP para aplicaciones de escritorio Linux vía AT-SPI2
- MCP como estándar de integración para equipos frontend
- Guía práctica: anatomía y desarrollo de un servidor MCP propio
- Herramientas, recursos, pruebas y despliegue de servidores MCP
- Servidores MCP para Docker y sandboxes de Linux controlados por IA
- MCP en clientes alternativos: ejemplo de KoboldCpp