- n8n ofrece ventaja en agentes IA: ecosistema maduro, integraciones nativas y auto-hospedaje con control de costes.
- Patrones clave: memoria persistente, control de errores, rate limiting y monitoreo para fiabilidad y escala.
- Flujos prácticos: conectar CRM, Slack, Notion y Sheets; orquestar herramientas con prompts bien diseñados.
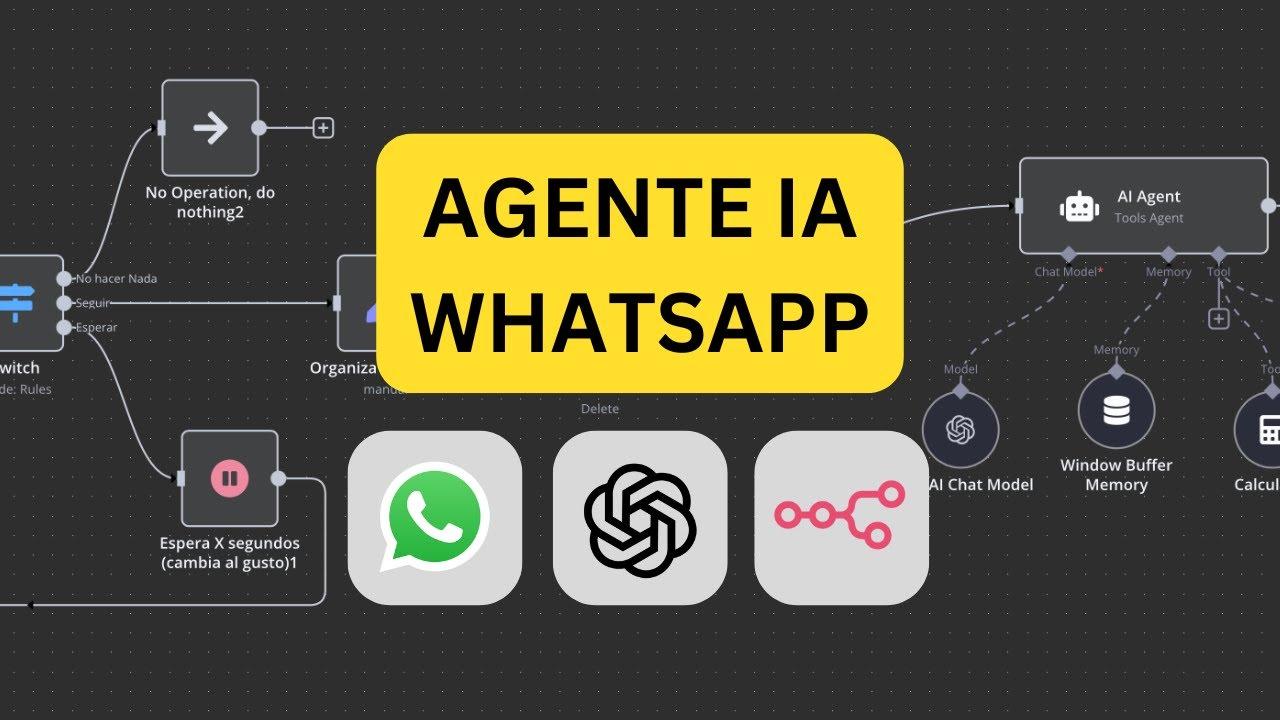
Si te interesan los agentes de IA y te pica la curiosidad por construir uno propio, seguramente ya te hayas cuestionado qué plataforma usar para orquestarlo. La combinación de simplicidad, potencia e integraciones convierte a n8n en un candidato especialmente atractivo para quienes quieren automatizar conversaciones, conectar modelos como OpenAI o Gemini y desplegar lógica de negocio sin tener que programarlo todo desde cero.
Además, existe un debate recurrente: ¿por qué preferir n8n frente a alternativas como Make o Zapier? Hay razones de peso: madurez del ecosistema de agentes, flexibilidad a la hora de enlazar servicios y la opción de auto-hospedaje que reduce costes recurrentes. Y sí, aunque muchos vídeos y posts prometen que “crear un agente de IA es coser y cantar”, la realidad práctica invita a ser más metódicos: hay truquitos, patrones y buenas prácticas que marcan la diferencia.
Por qué apostar por n8n para tus agentes de IA

Lo primero: n8n fue antes que muchos en esto de los agentes de IA. Mientras plataformas como Make incorporaron oficialmente sus agentes en abril de 2025, n8n llevaba meses de ventaja, lo que ha permitido a su comunidad madurar integraciones, patrones y ejemplos reales de uso con tiempo suficiente.
Segundo: destaca su habilidad para “enchufarse” a casi cualquier cosa. Con n8n puedes conectar un agente a CRM, Slack, Notion, Google Sheets o cualquier API que exponga endpoints HTTP, con una biblioteca de nodos nativos que reduce la necesidad de parches frágiles o scripts improvisados.
Tercero: costes y control. La posibilidad de auto-hospedar n8n en tu propio servidor o VPS te permite evitar suscripciones elevadas y mantener la infraestructura bajo tu supervisión. Esta modalidad self-hosted, además, resulta ideal para entornos donde la privacidad y el cumplimiento regulatorio están por encima de todo.
En conjunto, n8n ofrece un terreno de pruebas formidable para experimentar sin corsés y desplegar en producción cuando llegue el momento. Su equilibrio entre flexibilidad, precio y autonomía lo convierte en un “hub” pragmático para agentes IA ambiciosos que necesitan hablar con múltiples sistemas, persistir contexto y ejecutar herramientas.
Qué es un agente de IA en n8n y qué puede hacer
Cuando hablamos de “agentes” nos referimos a sistemas que combinan un modelo de lenguaje con herramientas externas, memoria y reglas de orquestación. En n8n esa orquestación se modela como un flujo de nodos que se comunican: uno invoca al modelo, otro consulta una base de datos, otro calcula, otro escribe en un CRM, y así sucesivamente.
Un agente construido en n8n puede responder a conversaciones, pedir información adicional, ejecutar funciones y devolver resultados. La gracia está en que integra “herramientas” muy diversas: desde calculadoras hasta conectores de bases de datos, pasando por CRM y hojas de cálculo. Así, la IA no solo “habla”, sino que también “hace”.
¿Modelos? Los más comunes son OpenAI y Gemini, entre otros, y se integran vía nodos nativos o mediante llamadas HTTP. La capa de prompts (instrucciones) define el carácter del agente, sus límites y su estilo, y la capa de herramientas le da capacidad operativa: “consulta esta tabla”, “crea este registro”, “calcula esta métrica”.
Esta aproximación no exige programar, aunque ayuda tener cierta mentalidad técnica. Tal y como se ve en tutoriales populares, es posible partir de cero, crear prompts básicos y acoplar conectores para que el agente consulte, calcule y automatice tareas del día a día; en esencia, como si fuese un compañero virtual que sabe operar con tus sistemas.
Incluso hay publicaciones que comparten el proceso con un enfoque didáctico y cercano (“crea tu agente sin ser programador”, “paso a paso”). En más de un caso, acompañan la explicación con un vídeo demostrativo (por ejemplo, el enlace https://linktw.in/EGJXxY), lo que facilita visualizar la estructura del flujo y los ajustes clave del nodo del modelo.
Dificultades reales que te vas a encontrar (y cómo superarlas)
Muchos tutoriales simplifican, y es normal que al ponerse manos a la obra aparezcan fricciones. Conectar APIs de IA, mantener el contexto, depurar y escalar no siempre es trivial, y conviene anticiparlo para evitar frustraciones.
Integración con APIs de IA. El primer choque suele ser “¿por qué mi llamada al modelo falla o no devuelve lo esperado?”. En n8n, usa nodos nativos de OpenAI/Gemini cuando existan; si no, recurre a HTTP Request con autenticación correcta, cabeceras y esquema de payload bien definido. Ten a mano ejemplos de la API y valida paso a paso la respuesta JSON.
Memoria y contexto. “Que el agente recuerde” no es magia, es diseño. Implementa un almacenamiento de estado: una base de datos, Redis o, en su defecto, una hoja de Google Sheets para prototipos; guarda un thread_id por conversación y aplica resúmenes dinámicos (summarization) para mantener la ventana de contexto bajo control.
Depuración sin lágrimas. Los flujos pueden fallar en silencio si no eres cuidadoso. Activa logs, añade nodos de comprobación (IF) y mensajes intermedios, controla errores con Try/Catch y notificaciones. Valida cada sub-bloque y, antes de escalar, congela una versión estable para no perseguir bugs fantasma.
Escalabilidad y límites de API. La peor experiencia es “irse de madre” con llamadas concurrentes. Introduce rate limiting, colas, batching y control de concurrencia en n8n; cuando trabajes con modelos, agrupa peticiones y cachea resultados temporales para evitar saturar la API y que los costes se disparen.
Patrones de arquitectura que funcionan
Para pasar de un prototipo simpático a un agente fiable, piensa en arquitectura. Divide la solución en capas: orquestación (n8n), modelo (OpenAI/Gemini), herramientas (APIs/BD), memoria (persistencia), monitoreo (logs/alertas).
Orquestador. n8n es el coordinador ideal: recibe el trigger (chat, webhook, Slack), decide qué herramientas invocar y cuándo, y compone la respuesta final. Usa ramas para casos especiales, y nodos de control de flujo para gestionar reintentos y tiempos de espera.
Memoria. No lo dejes al azar. Define cómo guardarás el historial: completo por conversación, más un resumen incremental para reinyectar como contexto; así evitas consumir tokens de manera absurda a la vez que el agente “recuerda” lo esencial.
Herramientas. Cada herramienta debe ser una pieza acotada. Conecta CRM, Slack, Notion o Google Sheets con nodos nativos y, para APIs propias, usa HTTP Request con autenticación segura. Documenta entradas y salidas de cada herramienta como si fuesen contratos.
Monitoreo y trazabilidad. Te ahorrará horas. Loguea inputs/outputs relevantes (anonimizados si hay datos sensibles), etiqueta sesiones con un ID y guarda métricas de latencia y error. Cuando algo se rompa, lo sabrás y podrás reproducirlo.
¿Hace falta combinar n8n con otras librerías o servicios?
La pregunta aparece en todos los foros: ¿n8n solo, o pegado a LangChain, Zapier y compañía? La respuesta pragmática: empieza con n8n en solitario y suma piezas si las necesitas. Para mucha gente, n8n cubre de sobra el caso de uso.
¿Cuándo añadir algo más? Si requieres flujos cognitivos complejos (agentes multi-herramienta con planificación recursiva), LangChain/LangGraph pueden aportar utilidad. Aun así, n8n sigue como orquestador de alto nivel y “pega” las partes.
¿Y Zapier/Make? Puedes combinarlos si ya tienes automatizaciones allí, pero plantéate la duplicidad. n8n brilla cuando centraliza integraciones y reduce dependencia de terceros; además, si vas a auto-hospedar, consolidar en n8n tiene sentido económico.
Ventajas de n8n: integraciones y flexibilidad extrema
La biblioteca de nodos de n8n cubre los sospechosos habituales: Slack, Notion, Google Sheets, CRMs populares, correo, webhooks… Esto elimina el 80% del “pico y pala” que sufres cuando todo son integraciones a medida.
Si necesitas una API rara, no pasa nada. El nodo HTTP Request te permite autenticarte, definir headers, enviar payload y parsear respuestas. Añade validaciones (IF) y mapea los datos a tu siguiente nodo.
El resultado es un lienzo visual en el que la IA tiene herramientas listas para usar. Tu agente no solo conversa: consulta, transforma, escribe y notifica con la misma naturalidad con la que un empleado usa varias apps a lo largo del día.
Guía práctica: despliegue self-hosted paso a paso
Una de las grandes bazas de n8n es que puedes alojarlo tú mismo en un servidor o VPS. Eso te da control total, mejor relación calidad/precio y menos dependencia de suscripciones. Aquí tienes un esquema operativo para ponerlo en marcha con buenas prácticas.
- Prepara la infraestructura: contrata un VPS con CPU/RAM acordes, configura un dominio/subdominio y abre puertos necesarios (HTTPS). Instala Docker y Docker Compose.
- Lanza n8n con Docker: usa la imagen oficial, define variables de entorno (en .env) para URL pública, credenciales y cifrado. Opcional: proxy inverso con Nginx y Let’s Encrypt para SSL.
- Persistencia: monta volúmenes para no perder datos en reinicios. Si vas a guardar memoria/conversaciones, conecta una base de datos (PostgreSQL, Redis) según el patrón de memoria elegido.
- Seguridad: habilita HTTPS, restringe panel de administración por IP si procede, usa credenciales robustas y gestiona las API keys mediante variables de entorno seguras. Considera secretos en Docker/Swarm.
- Webhooks y colas: configura webhooks entrantes para tus canales (por ejemplo, Slack o chat web) y aplica rate limiting. Si prevés picos, añade una cola (RabbitMQ/Redis) entre la entrada y n8n.
- Observabilidad: activa logs persistentes, exporta métricas (si usas Prometheus/Grafana, mejor) y prepara alertas ante errores o caídas. Un buen panel de salud te ahorra sustos.
- Backups: programa copias de seguridad de volúmenes claves y bases de datos. Prueba la restauración de forma periódica para garantizar que el plan funciona.
- Despliegues: estandariza con Compose o Terraform/Ansible si tu infraestructura crece. Mantén versiones fijas y ventanas de mantenimiento para actualizar sin sobresaltos.
Con esto, tendrás un entorno robusto donde experimentar y, si el proyecto despega, escalar con control de costes. El self-hosted de n8n no solo es viable; suele ser la opción preferida cuando hay requisitos de privacidad o se busca optimizar presupuesto.
Prompts, herramientas y pruebas: cómo afinar el agente
El prompt es la brújula del agente. Define un “sistema” claro: objetivos, tono, límites, fuentes disponibles y formato de salida. Describe las herramientas a su alcance como funciones con entradas/salidas esperadas.
Incluye instrucciones para la toma de decisiones: cuándo preguntar, cuándo ejecutar una herramienta, cómo fallar con gracia si no hay datos suficientes. En n8n, añade nodos que validen precondiciones antes de invocar cada herramienta para evitar llamadas inútiles.
Pruebas iterativas. Diseña una batería de conversaciones de ejemplo: dudas frecuentes, casos límite y entradas malformadas. Ejecuta los flujos con registros activados y compara resultados, latencias y costes. Ajusta prompts y ramificaciones según lo observado.
Control de errores. Establece Try/Catch alrededor de llamadas a APIs y modelos. En caso de fallo, genera respuestas útiles para el usuario, registra el incidente y notifica a un canal interno. Evita que el agente se quede “mudo”.
Optimización de costes. Los modelos no son gratis y los errores se pagan. Cachea resultados intermedios, resume historiales y limita el tamaño de contexto de forma inteligente. Si un cálculo o una consulta no cambian a menudo, reutiliza.
Casos de uso que aterrizan el concepto
Atención en Slack con memoria ligera. Un agente puede responder dudas, consultar una base de conocimiento y abrir tickets en tu CRM. Mantén memoria por canal con un ID de conversación y resúmenes periódicos.
Enriquecimiento de leads en CRM. Cuando entra un contacto nuevo, el flujo consulta datos, los normaliza y pide al modelo resúmenes con etiquetas útiles. Todo queda registrado y listo para el equipo comercial.
Operativa con Google Sheets. El agente recibe instrucciones, ejecuta cálculos, escribe resultados y comparte un enlace. Para prototipos, Sheets es una memoria barata; para producción, pasa a base de datos.
Asistente interno para reportes. Combina extracciones de APIs con un modelo que redacta un informe limpio para dirección. Integra notificaciones por email/Slack al cerrar el flujo.
Trucos que no suelen contarte
Plantillas de prompts. Crea una plantilla por “rol” de agente y versiona cambios. Un pequeño ajuste (p. ej., “si dudas, pregunta antes de actuar”) puede ahorrar llamadas innecesarias a herramientas.
Marcadores de contexto. Usa un “scratchpad” textual que el agente actualiza con decisiones y pendientes. Reinyecta ese scratchpad al prompt para reforzar consistencia entre turnos sin saturar la ventana.
Contratos de herramientas. Documenta inputs/outputs y valida tipos antes de invocar. Si una API espera un número y llega un string, corrige o avisa antes de romper el flujo. Menos sorpresas, más fiabilidad.
Test “canario”. Prepara una conversación breve y ejecuta ese test en cada despliegue. Si falla, no promociones cambios hasta entender por qué. Te evitará incidentes en horas críticas.
¿De verdad se puede construir un agente funcional en n8n?
La respuesta corta es sí. La larga: sí, con disciplina. Hay quien ha compartido su experiencia construyendo agentes que consultan, calculan y automatizan, desde tutoriales paso a paso hasta vídeos que enseñan el flujo completo.
Ahora bien, también existen posts que se desahogan con toda la razón: conectar modelos, mantener memoria y depurar flujos complejos puede parecer montar un mueble sin instrucciones. La clave es aplicar patrones de memoria, control de errores y límites de tasa, y apoyarse en la biblioteca de nodos nativos.
¿Trucos “secretos”? Más bien buenas prácticas. Empezar pequeño, registrar todo, controlar la concurrencia, validar entradas y diseñar prompts con intención. Cuando domines eso, lo demás encaja solo.
Costes y calidad/precio: por qué el self-hosted convence
Al auto-hospedar n8n reduces la dependencia de planes cloud y tienes las riendas de la infraestructura. Si tu carga es estable y tus flujos están bien afinados, el ahorro respecto a alternativas SaaS puede ser notable.
Además, alojar en tu VPS te permite ajustar el dimensionamiento a tus picos reales, sin pagar por encima de lo necesario. Si en el futuro creces, puedes escalar horizontalmente y separar funciones (orquestación, memoria, colas) con total libertad.
Todo ello, sin renunciar a integraciones de alto nivel y una comunidad que ya ha recorrido este camino. La ventaja acumulada de n8n en agentes IA se nota en ejemplos, snippets y respuestas a dudas recurrentes, que te ahorran tiempo.
Comunidad, dudas frecuentes y “likes” que cuentan
No estás solo: hay conversaciones donde la gente pregunta por atajos, compatibilidad con modelos, trucos de memoria o cómo depurar sin sufrir. También aparecen posts con reacciones (“likes”) que muestran el interés creciente por agentes IA en n8n, incluso entre quienes no se dedican a programar profesionalmente.
Si te preguntas si conviene “pegar” n8n con más herramientas, la conversación comunitaria coincide en un punto: prueba primero con n8n y añade piezas solo si te aportan un beneficio claro. Ese enfoque minimalista evita complejidad accidental y duplica menos funcionalidades.
Construir agentes de IA útiles con n8n no es un paseo, pero tampoco un muro infranqueable. Con una arquitectura sensata, memoria bien pensada, buenas prácticas de depuración y un despliegue self-hosted sólido, pasarás de la teoría al valor real en menos tiempo del que imaginas.
Tabla de Contenidos
- Por qué apostar por n8n para tus agentes de IA
- Qué es un agente de IA en n8n y qué puede hacer
- Dificultades reales que te vas a encontrar (y cómo superarlas)
- Patrones de arquitectura que funcionan
- ¿Hace falta combinar n8n con otras librerías o servicios?
- Ventajas de n8n: integraciones y flexibilidad extrema
- Guía práctica: despliegue self-hosted paso a paso
- Prompts, herramientas y pruebas: cómo afinar el agente
- Casos de uso que aterrizan el concepto
- Trucos que no suelen contarte
- ¿De verdad se puede construir un agente funcional en n8n?
- Costes y calidad/precio: por qué el self-hosted convence
- Comunidad, dudas frecuentes y “likes” que cuentan