- Linux utiliza toda la RAM disponible para cachés y page cache, por lo que poca memoria libre no implica necesariamente un problema.
- La combinación de swap, zram/zswap y un ajuste adecuado de vm.swappiness permite equilibrar rendimiento y estabilidad.
- cgroup v2, systemd-oomd y herramientas como earlyoom o nohang aportan control fino frente a presión de memoria y eventos OOM.
- Monitorizar con free, vmstat, htop, sar o Glances es clave para detectar cuellos de botella y optimizar la gestión de memoria.
Si administras sistemas, trabajas con contenedores o mantienes servidores en producción, entender a fondo la gestión de memoria en Linux ya no es opcional. Es la diferencia entre un servidor que aguanta picos de carga sin pestañear y otro que se arrastra, entra en thrashing o acaba invocando al temido OOM killer en el peor momento.
Linux está diseñado para exprimir la RAM todo lo posible: cachea archivos, comprime páginas, mueve datos a swap y prioriza procesos según políticas muy finas. Desde fuera puede parecer que “consume mucha memoria” o que “nunca hay RAM libre”, pero en realidad está intentando dar el máximo rendimiento y estabilidad. Vamos a ver, paso a paso y con algo de “baja cocina”, cómo funciona todo esto y cómo puedes tunearlo de forma avanzada.
Conceptos básicos y mitos de la memoria en Linux
Antes de tocar parámetros de kernel o montar zram como si no hubiera un mañana, conviene tener claras unas cuantas ideas sobre tipos de memoria, arquitectura y cómo ve la RAM el sistema.
La cantidad máxima de memoria física que un equipo puede gestionar viene marcada por la arquitectura del sistema operativo y del procesador. Un sistema de 32 bits suele estar limitado a 4 GB de RAM, mientras que uno de 64 bits puede manejar con holgura decenas o cientos de gigas (a nivel teórico, muchísimo más, aunque el límite real lo pone el hardware).
En Linux, toda la memoria se maneja como memoria virtual. Eso incluye tanto la RAM física como el espacio de intercambio (swap). La RAM no se puede “estirar” salvo añadiendo módulos físicos, pero la memoria virtual sí se amplía apoyándose en disco (particiones o archivos de swap) y en mecanismos avanzados como zram o zswap.
La memoria física (RAM) es el recurso rápido y caro: ahí se cargan los procesos, librerías, cachés de archivos, buffers de E/S, memoria compartida, etc. Linux tiene una filosofía muy clara: si hay RAM libre, mejor usarla como caché y acelerar accesos que dejarla vacía. Por eso, ver poca memoria “libre” en herramientas como free no significa que tengas un problema.
La memoria de disco (almacenamiento persistente) es mucho más lenta. Mientras la RAM responde en nanosegundos, incluso un SSD lo hace en micro o milisegundos. Por eso el sistema intenta mantener en RAM todo lo que se usa con frecuencia y solo recurre al disco cuando no queda otra: cargar ejecutables, leer datos fríos o volcar páginas a swap.
Memoria virtual, páginas y estructuras internas del kernel
La memoria virtual es el mecanismo con el que Linux entrega a cada proceso un espacio de direcciones propio, aislado y protegido. El hardware y el kernel convierten direcciones virtuales en direcciones físicas a través de estructuras llamadas tablas de páginas.
La unidad mínima con la que se gestiona la memoria es la página (page), normalmente de 4 KB. Todo el sistema de memoria virtual gira en torno a páginas: se asignan, se liberan, se pasan a swap, se almacenan en caché y se marcan con distintos permisos (solo lectura, ejecución, etc.).
Las page tables son estructuras jerárquicas mantenidas por el kernel. Guardan, para cada página virtual de cada proceso, dónde está la página física real (si existe), qué permisos tiene y en qué estado se encuentra. Esta traducción es lo que permite aislar procesos, compartir páginas entre ellos o mapear archivos directamente en memoria.
Cuando un proceso accede a una dirección válida, pero la página no está lista para ese acceso, se produce un page fault. Puede ser ligero (la página está en RAM pero con un estado que requiere actualización) o costoso (la página está en disco, en swap o en un archivo, y hay que traerla a RAM). Si los fallos de página se disparan, el sistema se vuelve lento porque pasa demasiado tiempo leyendo desde disco.
La page cache es la caché de páginas de archivos que mantiene el kernel. Almacena datos y metadatos de ficheros y directorios para reducir accesos a disco. Es uno de los motivos por los que Linux “parece” usar toda la RAM: en realidad, está aprovechando la memoria que las aplicaciones no usan activamente para acelerar el acceso a disco.
Tipos de memoria: file-backed, anónima y cómo se relacionan con la swap
En Linux se suele distinguir entre memoria asociada a archivos (file memory) y memoria anónima (anonymous memory). Ambas residen en RAM, pero su origen y su posible “copia de seguridad” en disco son distintos.
La llamada file memory es la que está respaldada por archivos del sistema: código ejecutable de binarios, librerías compartidas, datos mapeados con mmap desde un fichero, etc. Esa memoria se puede descartar y volver a cargar desde el archivo original si hace falta espacio.
La memoria anónima es todo lo que el proceso reserva que no está ligado a un archivo: el heap dinámico, la pila (stack), regiones privadas con MAP_ANONYMOUS, y las áreas copiadas por copy-on-write al hacer fork(). Esta memoria solo existe en RAM (o en swap, si se desplaza) y su único respaldo posible es precisamente ese espacio de intercambio.
Cuando el kernel necesita liberar RAM, primero intentará soltar páginas que pueda recomponer: típicamente, páginas de la page cache o regiones file-backed. Solo cuando no queda margen o la presión de memoria es muy alta empieza a empujar memoria anónima hacia swap, que es mucho más costoso pero da un respiro al sistema.
Presión de memoria, thrashing y OOM killer
Se habla de memory pressure cuando el número de páginas libres cae por debajo de ciertos umbrales internos. El kernel se ve obligado a trabajar constantemente liberando memoria: limpiando cachés, escribiendo páginas sucias a disco, expulsando páginas poco usadas, etc.
Con presión de memoria elevada pueden aparecer síntomas muy claros: latencias altas en servicios web, interfaces gráficas que se vuelven lentas, sesiones remotas (SSH, VNC, RDP) que responden con retraso, ratón a tirones, ventanas que tardan segundos en reaccionar, etc. En ese punto el sistema está más peleando por sobrevivir que haciendo trabajo útil.
El thrashing ocurre cuando la RAM es insuficiente para mantener las páginas que los procesos usan continuamente. El kernel empieza a intercambiar páginas todo el rato: saca una para meter otra, pero al momento vuelve a necesitar la que acaba de expulsar. El resultado es un ciclo de fallos de página y accesos a disco que hunde el rendimiento.
Con swap activada, el thrashing significa que las páginas anónimas van y vienen entre RAM y área de intercambio, saturando el disco. Sin swap, el problema se traslada a las páginas de archivos: se descartan y se recargan una y otra vez desde el sistema de ficheros, lo que también puede dejar la máquina prácticamente inutilizable.
Si aún así el kernel es incapaz de conseguir memoria libre, entra en escena el mecanismo Out-Of-Memory (OOM). Cuando se agota todo lo que puede soltar, compactar o intercambiar, el kernel calcula un puntaje para cada proceso (oom_score) y decide a cuál sacrificar. Ese proceso es terminado por el OOM killer para liberar una cantidad significativa de RAM y evitar el colapso total.
Swap: qué es, cuánto poner y por qué no es “el demonio”
La swap arrastra una mala fama importante, en parte por consejos antiguos y simplificaciones tipo “si tienes mucha RAM no necesitas swap”. En realidad, el espacio de intercambio es una pieza clave del diseño de memoria de Linux, incluso en equipos con mucha RAM.
El swap es un área en disco (partición o archivo) que el kernel usa para almacenar páginas de memoria inactivas. Esto le permite vaciar RAM para procesos que realmente la necesitan. No es memoria virtual en sí misma, sino uno de los mecanismos que la hacen posible.
Sin swap, las páginas anónimas no tienen “dónde ir” cuando sobra presión de memoria. El kernel puede seguir tirando de cachés y páginas file-backed, pero en cuanto la memoria anónima se dispara está prácticamente obligado a invocar al OOM killer mucho antes. Técnicamente Linux puede funcionar sin swap, pero en la práctica es un riesgo innecesario en la mayoría de escenarios.
A la hora de dimensionar el swap, no hay una única receta, pero sí criterios modernos bastante razonables según el rol de la máquina:
- Servidores sin hibernación: 4-8 GB de swap suelen bastar como colchón, incluso con mucha RAM. En servicios muy intensivos en memoria (bases de datos, virtualización) puede subir hasta 1,5× la RAM, pero la prioridad debe ser incrementar la RAM física.
- Escritorios sin hibernación: con 16 GB o más de RAM, 2-4 GB de swap son más que suficientes como red de seguridad.
- Equipos con hibernación: el swap debe ser igual o ligeramente superior a la RAM, porque el sistema vuelca en él todo el contenido de la memoria al hibernar.
Crear swap es muy flexible. Puedes usar una partición dedicada o un archivo de intercambio. El archivo es ideal cuando ya tienes el disco particionado o quieres ajustar el tamaño sin reconfigurar todo el sistema.
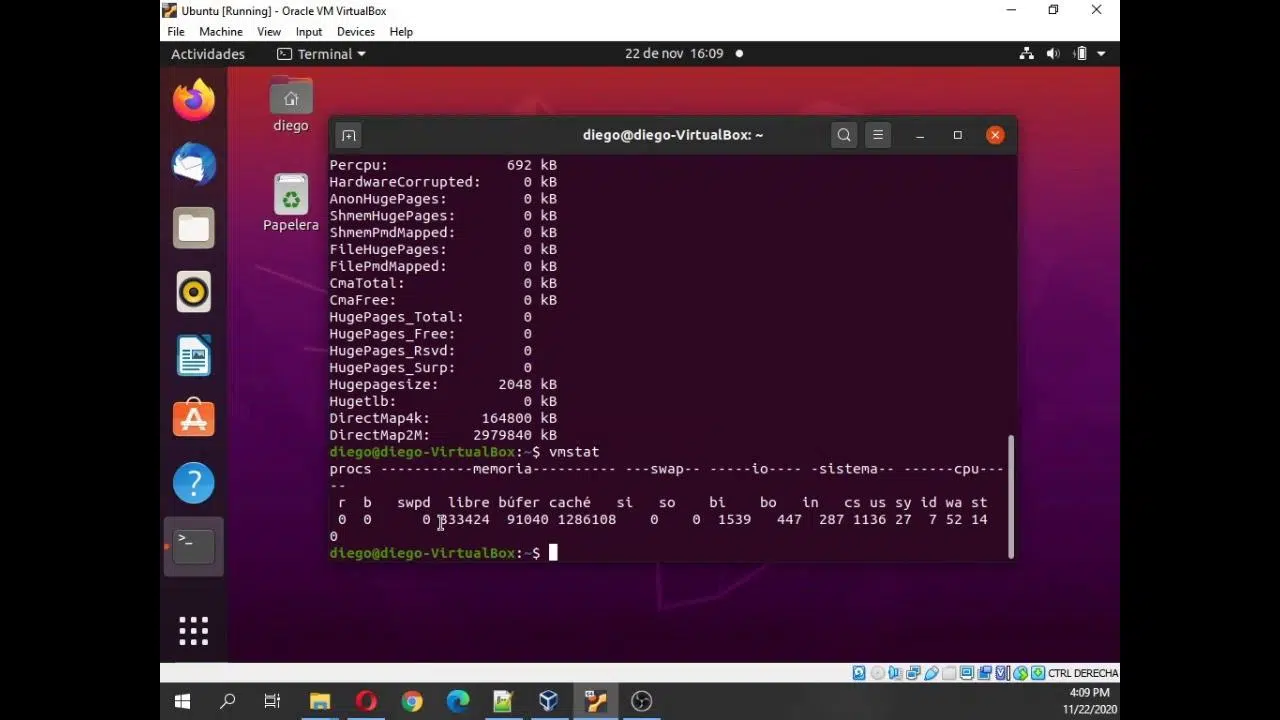
Métricas de memoria: free, vmstat, ps, RSS, PSS y más
Las herramientas clásicas para ver memoria en Linux pueden llevar a malinterpretaciones si no sabes qué significa cada columna. El comando free -h es el más sencillo para ver de un vistazo memoria total, usada, libre, caché y swap.
En la salida de free es clave fijarse en la línea que descuenta buffers y caché, porque esa columna indica la memoria realmente ocupada por procesos, sin contar lo que el kernel está usando como caché y que puede liberar rápidamente si hace falta.
Con vmstat -s -S M obtienes un resumen más detallado: memoria total, usada, libre, activa, inactiva, caché de swap, etc. También es posible consultar /proc/meminfo para ver cada métrica al detalle, aunque la salida es más árida y menos amigable.
Para saber qué procesos son los que más afectan a la RAM, ps aux muestra columnas como VSZ (memoria virtual total que podría llegar a usar el proceso si cargase todo) y RSS (Resident Set Size, memoria real actualmente en RAM). Ojo: el RSS incluye también memoria de librerías compartidas, que se contabiliza varias veces si la usan varios procesos.
Aquí entra en juego PSS (Proportional Set Size), que reparte el coste de las librerías compartidas entre los procesos que las usan. Para obtener PSS de forma cómoda existen herramientas como smem, muy útiles para ver qué aplicaciones son realmente “tragonas” sin deformar los datos por culpa de las librerías compartidas.
Fragmentación de memoria, stack, heap y ulimit
Otro aspecto poco visible de la gestión de memoria es la fragmentación. Podemos hablar de fragmentación interna (cuando se asignan bloques redondeados a múltiplos de 4, 8 o 16 bytes y sobra un trozo inútil) y fragmentación externa (cuando la memoria libre existe, pero está partida en trozos pequeños que impiden satisfacer una reserva grande contigua).
En aplicaciones como Redis, a veces verás diferencias entre la memoria que reporta el sistema (RSS) y la que la propia app considera útil (used_memory). Esa distancia suele deberse en buena medida a fragmentación externa, huecos que el sistema cuenta como ocupados pero que el proceso no utiliza realmente.
La memoria de un proceso se divide conceptualmente en stack y heap. La pila se usa para variables locales y llamadas de función, mientras que el heap sirve para reservas dinámicas con malloc() y similares. Cuando las estructuras de datos crecen más allá de lo que puede albergar la stack, se tiran del heap y se manejan mediante punteros.
El tamaño máximo de stack por proceso se puede ajustar con ulimit -a y configuraciones del sistema. Reducirla limita la cantidad de variables locales grandes, mientras que aumentarla permite más variables o recursión profunda. Ajustar este parámetro puede ayudar a controlar mejor el uso de memoria y reducir ciertos tipos de fragmentación, aunque no es la panacea.
Monitorización y diagnóstico avanzado: top, htop, vmstat, sar y más
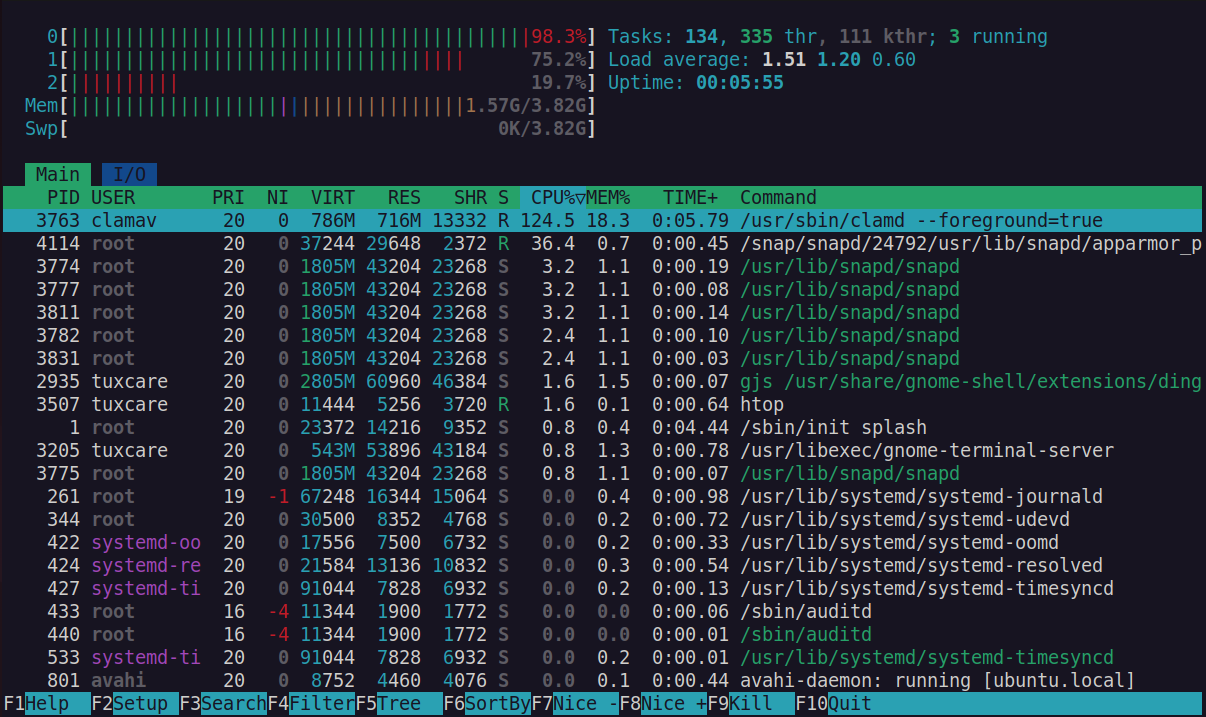
Para localizar procesos que se están comiendo la RAM, puedes empezar con top y, si quieres algo más amigable, con htop. Este último muestra barras de uso de CPU, memoria, swap, y permite ordenar y filtrar procesos de manera interactiva.
En Debian y derivados, instalas htop con sudo apt install htop. En AlmaLinux y otros Red Hat-like, con sudo dnf install htop. Una vez dentro, puedes ordenar por memoria, buscar procesos concretos y matar tareas problemáticas directamente desde la interfaz.
Para un análisis más profundo y en modo batch, vmstat 5 ofrece información periódica sobre procesos, memoria, paginación, E/S de bloques, interrupciones y planificación de CPU. Es ideal para ver cómo evoluciona la presión de memoria a lo largo del tiempo.
La suite sysstat incorpora herramientas como sar, que permiten registrar y analizar el uso de memoria y otros recursos. Por ejemplo, sar -r 1 5 muestra uso de memoria y swap cada segundo, cinco veces. En Debian se instala con sudo apt install sysstat, y en AlmaLinux con sudo dnf install sysstat.
Si necesitas depuración profunda a nivel de kernel, bpftrace es una herramienta potentísima basada en eBPF. Permite instrumentar llamadas al sistema, observar acceso a memoria o detectar cuellos de botella sin recompilar ni reiniciar. Se instala normalmente con sudo apt install bpftrace en sistemas Debian-like.
Gestión práctica de memoria: swap, swappiness y limpieza de caché
Una tarea básica en muchos servidores es comprobar el estado actual de la swap. Con swapon --show tienes un listado de dispositivos y archivos de intercambio activos, su tamaño, tipo y prioridad. Si necesitas añadir swap en caliente, puedes crear un archivo con fallocate, asegurar permisos con chmod 600, formatearlo con mkswap y activarlo con swapon. Para hacerlo persistente, basta con añadir la entrada correspondiente a /etc/fstab.
El parámetro vm.swappiness controla cuánta predisposición tiene el kernel a usar swap frente a seguir llenando la RAM. Va de 0 a 100. Valores bajos (10-20) hacen que el sistema evite el swap hasta que no quede otra, mientras que valores altos (60 o más) mueven páginas a swap más alegremente para mantener RAM libre.
En servidores con discos lentos o bases de datos grandes suele interesar bajar la swappiness, por ejemplo a 10 o 20, con sudo sysctl vm.swappiness=10. Para escritorios con zram o SSD rápidos, valores intermedios como 30-60 pueden dar un buen equilibrio entre latencia y aprovechamiento de memoria.
En situaciones de memoria justa, a veces se recurre a forzar la liberación de cachés con sudo sync && sudo sysctl -w vm.drop_caches=3. Esto vacía gran parte de la page cache y dentries. Es útil puntualmente para pruebas o para liberar memoria en equipos muy limitados, pero no conviene usarlo como rutina, porque también pierdes la mejora de rendimiento que aporta la caché.
Herramientas avanzadas de control: cgroup v2, memory.pressure y OOM en espacio de usuario
En sistemas modernos que usan systemd y cgroup v2, la gestión de memoria se puede afinar por grupos de procesos. cgroup v2 organiza tareas en jerarquías y aplica límites y prioridades de recursos (CPU, memoria, I/O) a nivel de grupo, no solo de proceso individual.
Dentro de la jerarquía de memoria, parámetros como memory.low permiten indicar que la memoria de ciertos cgroups debería protegerse más frente a la presión global, mientras que otros pueden ser más sacrificables si hace falta liberar RAM.
El fichero memory.pressure expone métricas muy útiles: cuánto tiempo han estado tareas de ese cgroup bloqueadas por falta de memoria, en ventanas de 10, 60 y 300 segundos. La variante some indica si al menos una tarea ha sufrido retrasos, y full refleja momentos en los que todas las tareas del grupo estaban simultáneamente afectadas.
Además del OOM killer del kernel, han surgido soluciones en espacio de usuario como earlyoom, nohang o systemd-oomd. EarlyOOM monitoriza RAM y swap, y cuando caen por debajo de ciertos umbrales mata de forma proactiva los procesos con oom_score más alto, devolviendo la usabilidad antes de que la máquina se congele.
NoHang va un paso más allá: admite más criterios de selección, puede tener en cuenta la presión de memoria y se integra bien con configuraciones avanzadas, aunque su desarrollo ha tenido altibajos. Por su parte, systemd-oomd se integra directamente con systemd y cgroup v2, y hoy en día es la opción favorita en muchas distribuciones para gestionar situaciones de falta de memoria de forma más inteligente y granular.
Swap moderna: zram, zswap y prioridades de dispositivos
Además de la swap “clásica” en disco, Linux ofrece mecanismos modernos que mejoran mucho el rendimiento al combinar compresión en RAM y uso selectivo de disco.
zram es un módulo del kernel que crea dispositivos de bloque en la propia RAM, donde las páginas se almacenan comprimidas. Se suelen usar como dispositivos swap ultrarrápidos: consumes algo de CPU para comprimir y descomprimir, pero ganas capacidad lógica de memoria y reduces drásticamente el uso de disco.
En muchas distribuciones basta con instalar zram-tools o zram-generator y habilitar su servicio. Por ejemplo, en Debian se puede usar sudo apt install zram-tools y activar zramswap con systemd. En AlmaLinux, con sudo dnf install zram-generator y su servicio correspondiente.
zswap, por otro lado, funciona como una caché comprimida delante de la swap en disco. Primero intenta alojar las páginas swapeadas en RAM comprimida; solo cuando esta caché se llena o páginas quedan frías pasa a escribir al área de intercambio real. De este modo reduce E/S de disco y alarga la vida de los SSD, a costa de un poco de CPU.
Cuando combinas varios dispositivos de swap (por ejemplo, zram y un archivo en disco), es vital ajustar las prioridades. Con swapon -p o la opción pri= en /etc/fstab indicas qué dispositivo debe usarse primero. Lo habitual es dar prioridad alta (por ejemplo 100) a zram y menor (10) a la swap en disco, de manera que el kernel saque todo el partido posible al intercambio comprimido en RAM antes de tocar el disco.
Gestión de memoria aplicada a servidores: swap, servicios y seguridad
En servidores web (Apache, Nginx), bases de datos (MySQL, MariaDB, MongoDB) o aplicaciones de alto consumo, la memoria es el recurso crítico. La configuración de la RAM y el swap condiciona directamente cuántas peticiones simultáneas puedes manejar sin que el sistema empiece a sufrir.
En el caso de motores como MongoDB, es fundamental que la RAM física supere las necesidades de la base de datos; de lo contrario empezará a usar swap y el rendimiento caerá en picado por la diferencia brutal entre acceso a RAM y acceso a disco. Lo mismo se aplica a MySQL/MariaDB, donde herramientas como MySQLTuner recomiendan parámetros de memoria en función de la RAM disponible.
Para evitar desperdiciar memoria, conviene detener servicios que no estén en uso y limpiar contenedores, imágenes y volúmenes de Docker que ya no se necesiten. En entornos de desarrollo y QA es muy fácil ir acumulando recursos olvidados que van robando gigas de RAM y disco sin que nadie se dé cuenta.
La seguridad también influye: puertos innecesarios abiertos aumentan la superficie de ataque. Un malware que consiga entrar puede, por ejemplo, lanzar procesos de minería que consuman CPU y memoria, programar tareas en crontab y colapsar el sistema. Revisar puertos de entrada y salida, cerrar todo lo que no sea imprescindible y limpiar cronjobs sospechosos es parte de la higiene básica que, además, protege recursos de memoria.
Memoria y sistemas de archivos: ext4, XFS, Btrfs y journaling
Aunque pueda parecer un tema separado, la elección del sistema de archivos y su configuración también influyen en el comportamiento de la memoria y la carga de I/O. Ext4, por ejemplo, usa un journal que, según la carga, puede meter cierta presión extra en disco y, por rebote, en la gestión de cachés.
En escenarios de servidor exigente, muchos administradores optan por XFS o incluso Btrfs. XFS suele rendir muy bien con ficheros grandes y sistemas de alto rendimiento. Btrfs ofrece características avanzadas como snapshots, compresión transparente o subvolúmenes, a costa de cierta complejidad y, dependiendo de la versión y la distro, de un grado de madurez todavía discutido para todas las cargas de trabajo.
El kernel adapta su política de caché y escritura diferida a las características del sistema de archivos, por lo que cambiar de ext4 a XFS o Btrfs no solo afecta al I/O bruto, sino también a cómo se usan la RAM y la page cache para amortiguar operaciones de lectura y escritura.
Herramientas gráficas y utilidades “imprescindibles” para admins
Si bien la terminal sigue siendo la navaja suiza de cualquier admin, hay herramientas que hacen mucho más amable la gestión de memoria y recursos. Una de ellas es Glances, un monitor en tiempo real que muestra CPU, memoria, disco, red y procesos en una sola pantalla, con opción de interfaz web para vigilar varios servidores desde un navegador.
Para instalación rápida en Debian basta con sudo apt install glances. Glances se complementa muy bien con htop, vmstat y sar, dando una panorámica más visual de cómo se comporta el sistema bajo carga.
En el terreno de la administración gráfica de servidores, Cockpit ofrece una interfaz web muy cómoda para supervisar memoria, procesos y servicios. Permite gestionar varios servidores desde una sola consola, arrancar y parar unidades systemd, vigilar uso de swap y zram, y revisar logs sin abandonar el navegador.
En sistemas de escritorio, muchas distros integran su propio monitor de recursos, pero para entornos sin GUI o donde quieras algo ligero, combinar estas herramientas de consola con scripts personalizados te da una visibilidad excelente sobre qué está pasando con la memoria en cada momento.
Controlar bien la memoria en Linux implica entender cómo el kernel usa la RAM, qué papel juegan swap, zram y zswap, cómo responden cgroup v2 y los distintos OOM a la presión, y qué herramientas tienes para observar y tunear el sistema. Cuando ensamblas todas estas piezas —desde free, vmstat, PSS y memory.pressure hasta zram, swappiness y systemd-oomd— dejas de pelearte con “Linux que se come la RAM” y pasas a tener un sistema afinado, estable y capaz de exprimir al máximo el hardware en cualquier rol: servidor, escritorio o entorno de alta carga.

Tabla de Contenidos
- Conceptos básicos y mitos de la memoria en Linux
- Memoria virtual, páginas y estructuras internas del kernel
- Tipos de memoria: file-backed, anónima y cómo se relacionan con la swap
- Presión de memoria, thrashing y OOM killer
- Swap: qué es, cuánto poner y por qué no es “el demonio”
- Métricas de memoria: free, vmstat, ps, RSS, PSS y más
- Fragmentación de memoria, stack, heap y ulimit
- Monitorización y diagnóstico avanzado: top, htop, vmstat, sar y más
- Gestión práctica de memoria: swap, swappiness y limpieza de caché
- Herramientas avanzadas de control: cgroup v2, memory.pressure y OOM en espacio de usuario
- Swap moderna: zram, zswap y prioridades de dispositivos
- Gestión de memoria aplicada a servidores: swap, servicios y seguridad
- Memoria y sistemas de archivos: ext4, XFS, Btrfs y journaling
- Herramientas gráficas y utilidades “imprescindibles” para admins