- Los pipes en Linux permiten encadenar procesos conectando stdout y stdin, con soporte del kernel y herramientas como tee, xargs y cpio para flujos complejos.
- Un pipeline CI/CD eficiente en Linux se basa en buen diseño de etapas, uso intensivo de cachés, artefactos inmutables y pruebas paralelas.
- La optimización del servidor Linux (CPU, RAM, E/S, Docker) y de los ejecutores Jenkins, GitHub Actions o GitLab Runner es clave para reducir tiempos.
- Integrar seguridad, observabilidad y control de costes en el pipeline garantiza despliegues fiables, trazables y sostenibles en entornos de producción.
Optimizar los pipelines en Linux no va solo de encadenar comandos con el símbolo |. Detrás hay todo un mundo de optimización de rendimiento, diseño de flujos de trabajo, CI/CD, seguridad y afinado del sistema operativo que marca la diferencia entre una canalización lenta e inestable y otra que vuela, es fiable y barata de mantener. Si trabajas con servidores Linux, ya sea para automatizar tareas en la terminal o para ejecutar pipelines de integración continua, entender estos detalles te ahorra mucho tiempo y dolores de cabeza.
En este artículo vamos a mezclar dos perspectivas complementarias: por un lado, el uso clásico de pipes en la línea de comandos de Linux (tuberías, redirecciones, comandos como tee, xargs o cpio); por otro, la optimización de pipelines CI/CD en servidores Linux, incluyendo caching, paralelización de pruebas, ajustando Docker, seguridad de la cadena de suministro y métricas avanzadas de los workflows. Todo ello explicado en castellano de España, con ejemplos claros y un enfoque muy práctico.
Qué es un pipeline y cómo encajan los pipes en Linux
El término pipeline procede de la idea de una tubería: un flujo de datos que circula de un punto a otro. En informática, y en concreto en Linux, un pipe es un mecanismo que permite que la salida estándar de un proceso se convierta directamente en la entrada estándar de otro. Es decir, lo que genera un comando se alimenta automáticamente al siguiente sin pasar por archivos intermedios.
En sistemas tipo Unix existen dos grandes tipos de pipes. Por un lado, los pipes anónimos o unnamed pipes, que solo pueden usarse entre procesos muy relacionados (por ejemplo, padre e hijo). Por otro, los pipes con nombre o named pipes, también conocidos como FIFO (First In – First Out), que permiten la comunicación entre procesos que no tienen relación directa e incluso pueden estar en máquinas distintas conectadas en red.
Los pipes anónimos proporcionan típicamente una comunicación unidireccional: un proceso escribe y el otro lee. En cambio, con los pipes con nombre puedes establecer una comunicación bidireccional si lo diseñas así, por ejemplo abriendo la FIFO en modo lectura/escritura desde ambos extremos. Se emplean mucho para coordinar procesos de demonios, scripts o servicios que necesitan pasarse datos sin bloquearse mutuamente.
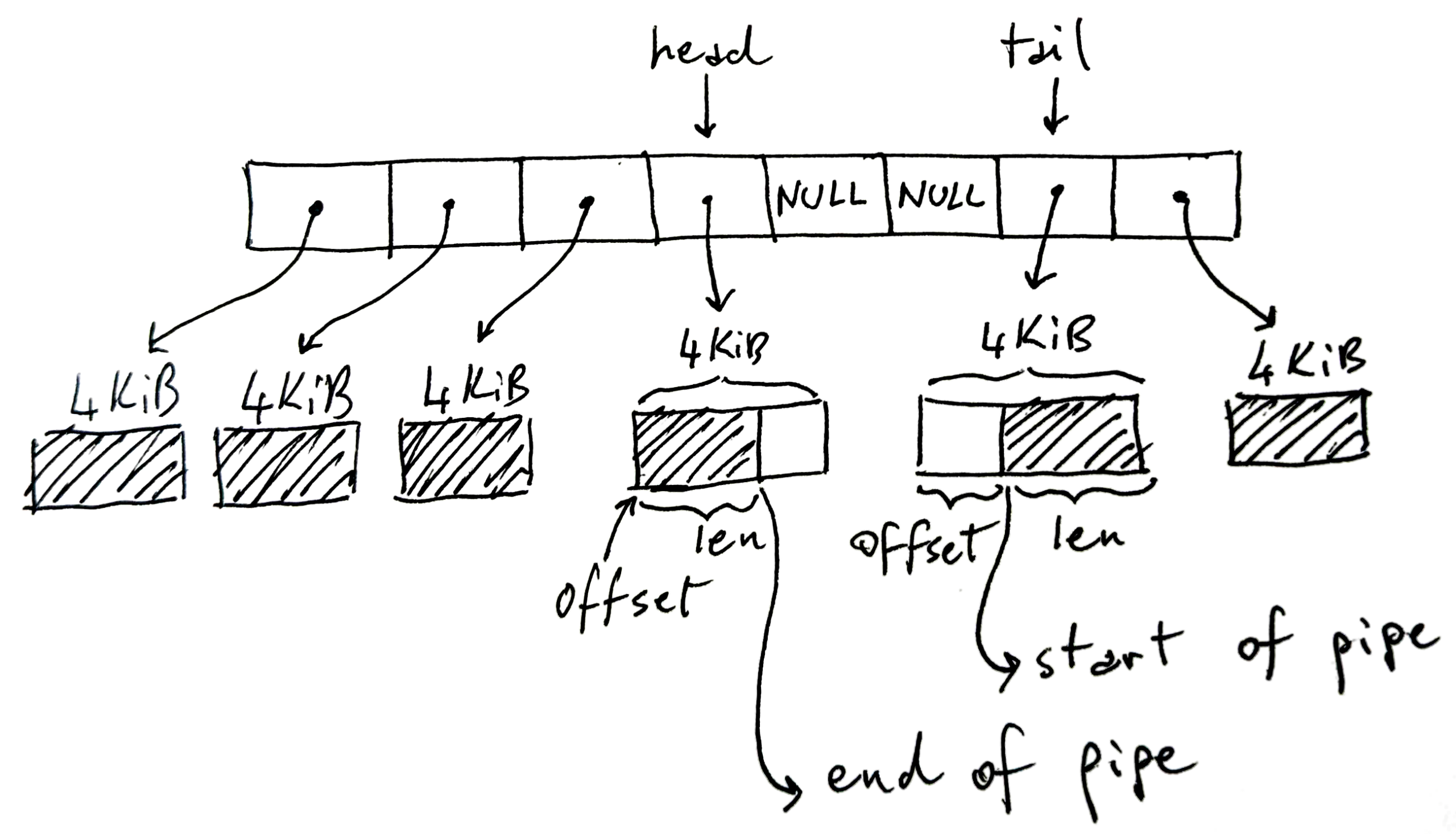
A nivel de implementación, el soporte para las tuberías está en el kernel de Linux, no en el shell. El intérprete de comandos (bash, zsh, etc.) se limita a crear el pipeline mediante llamadas al sistema como pipe() y fork(), redirigir los descriptores de fichero y luego lanzar cada programa. La magia real de cómo se bloquean los procesos, cómo se gestiona el buffer y cómo se propagan los datos entre productor y consumidor la maneja el núcleo del sistema.
Entendiendo stdin, stdout y el flujo de datos
Para trabajar bien con pipelines es clave tener claro qué son stdin, stdout y stderr. No son conceptos abstractos: cada proceso en Linux arranca con tres descriptores de fichero abiertos, que apuntan a recursos concretos gestionados por el kernel.
stdin (descriptor 0) y stdout (descriptor 1) se pueden ver como flujos de bytes conectados a algo: puede ser un terminal, un archivo, un socket de red o un pipe. No son simplemente búferes; son referencias a objetos del kernel (estructuras de tipo file) que a su vez están asociados a inodos, sockets o estructuras internas de pipe.
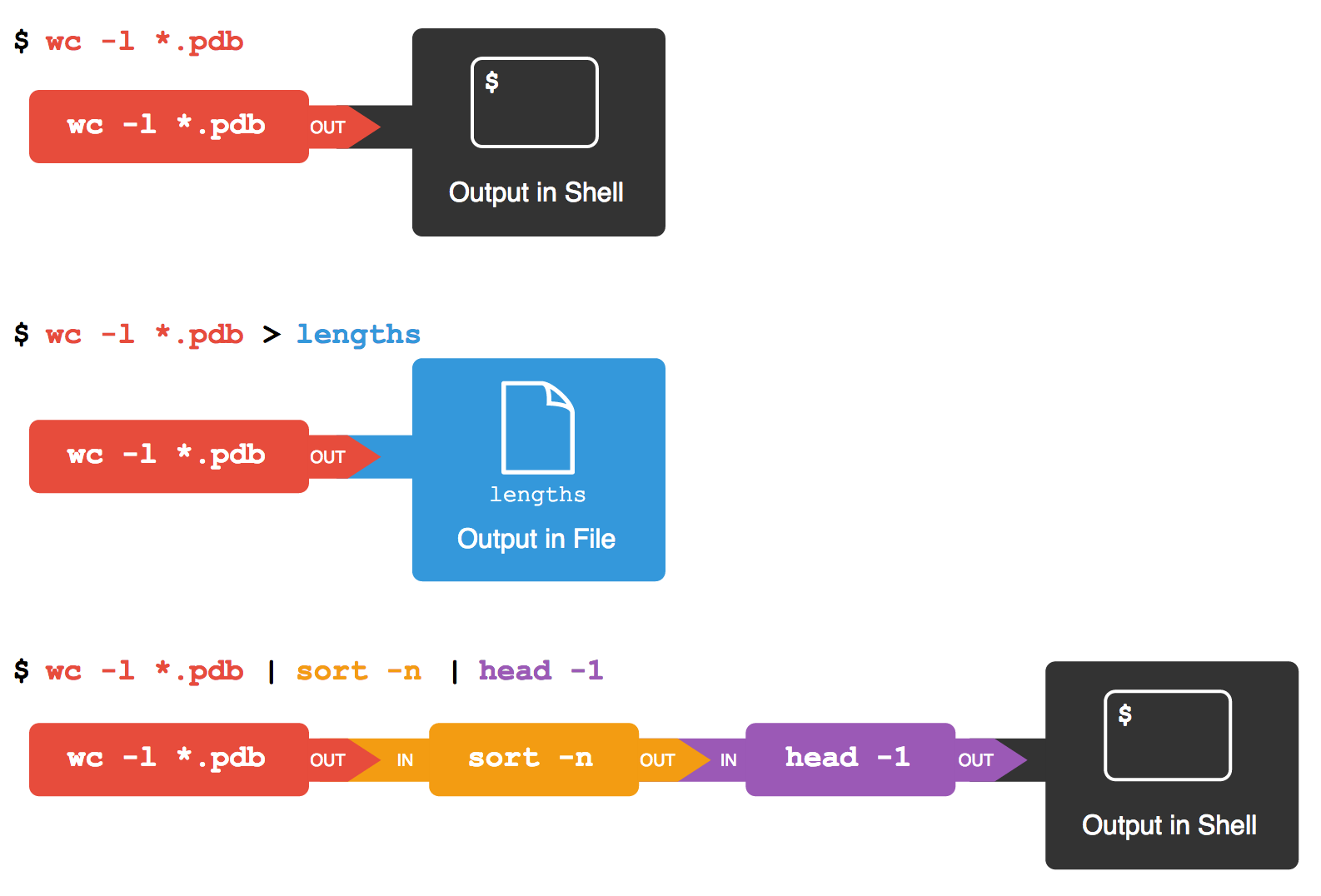
Cada proceso tiene sus propios descriptores, de forma que cada comando de un pipeline ve su stdin y stdout de manera independiente. En una línea como ls | grep txt | wc -l, el ls escribe en un pipe, grep lee de un pipe y escribe en otro, y wc lee del último. Para el usuario parece una sola cadena, pero internamente son varios buffers de kernel concatenados, con cada proceso bloqueándose y reanudándose según haya espacio o datos disponibles.
Cuando el primer proceso produce datos más rápido de lo que el segundo consume, el buffer del pipe se llena. En ese momento, las siguientes escrituras retornan bloqueando al proceso emisor hasta que el consumidor lee suficiente información y libera espacio. Esto evita que la memoria se dispare; no se van apilando datos indefinidamente, salvo que uses IO no bloqueante o señales especiales. Es decir, en un ejemplo como dd if=/dev/sda | gzip -9, si gzip comprime más lento, dd se ve obligado a esperar.
Este mecanismo de backpressure hace que los pipelines sean bastante estables incluso cuando hay desequilibrios de rendimiento entre etapas, algo que luego se refleja también en el diseño de pipelines de CI/CD, donde las etapas lentas se convierten en el cuello de botella que hay que medir y optimizar.
Uso práctico de pipes en la terminal de Linux
En el día a día, los pipes se usan para encadenar comandos en una sola línea y transformar datos paso a paso. En lugar de lanzar un comando, mirar la salida, copiarla, pegarla en otro… puedes montar pequeñas “fábricas de datos” en texto plano con mucha flexibilidad.
Un ejemplo típico en entornos Unix es combinar el comando fortune, que muestra citas aleatorias, con cowsay, que imprime una vaca “hablando”. Al usar un pipe, la salida de fortune se convierte en el mensaje de cowsay, todo en una sola orden. Es un ejemplo lúdico, pero ilustra perfectamente la idea de conectar herramientas simples para tareas más complejas.
Otro clásico es enviar el resultado de ls a wc para contar líneas, palabras y caracteres. Algo como ls | wc permite saber rápidamente cuántos elementos hay listados. La gracia está en que no necesitas que un solo programa lo haga todo, sino que compones soluciones con pequeñas utilidades bien diseñadas.
También es muy habitual encadenar cat, sort y more (u otro paginador) para ordenar un archivo de texto y luego explorarlo por páginas. Con una tubería, el contenido pasa de un comando al siguiente sin guardarse en archivos temporales explícitos, lo que simplifica mucho scripts y tareas de administración.
En casos prácticos como procesar listados de alumnos y notas en archivos distintos, puedes usar paste para fusionar columnas, cut para seleccionar solo los campos que te interesan y pipes encadenados para filtrar, ordenar o transformar todo en una única línea de shell. Este patrón de descomponer un problema grande en comandos sencillos combinados con pipes es la esencia de la filosofía Unix.
Comandos avanzados para sacar partido a los pipes: tee, xargs y cpio
Cuando empiezas a automatizar cosas de verdad en Linux, los pipes se vuelven todavía más potentes gracias a algunas herramientas clave. Entre ellas destacan tee, xargs y cpio, que complementan muy bien el flujo estándar de datos.
El comando tee actúa como un “T” en una tubería de agua: lee de stdin, escribe en stdout y además copia esa misma salida en uno o varios archivos. Es ideal cuando quieres ver la salida en pantalla y, a la vez, guardarla para revisarla después o procesarla en otra etapa. Con la opción -a añade datos al final del archivo en lugar de sobrescribirlo.
Por ejemplo, puedes ordenar una lista con sort, enviar el resultado a tee para almacenarlo en un log y, a la vez, pasarlo a more para paginarlo. Así, en un solo pipeline, tienes ordenación, guardado en disco y visualización cómoda sin repetir el trabajo de ordenado.
El comando xargs es otra pieza fundamental cuando se trata de pipes. Su función es tomar lo que llega por stdin (normalmente una lista de elementos) y convertirlo en argumentos de otro comando. Es especialmente útil cuando un programa falla porque recibe demasiados parámetros de golpe o cuando quieres fraccionar el trabajo en lotes con la opción -n, que limita cuántos argumentos se pasan por ejecución.
Por ejemplo, con ls | xargs -n 4 divides la lista de archivos en grupos de cuatro, ejecutando el comando objetivo (por defecto echo, o el que indiques) varias veces. De esta forma puedes construir pipelines tipo “previsualiza lo que voy a borrar” combinando ls, xargs y echo rm antes de lanzar el borrado real.
Hay que tener cuidado con las entradas complejas: rutas con espacios o caracteres especiales pueden romper el comportamiento por defecto de xargs. En esos casos suele emplearse en combinación con find y la opción -print0, que separa elementos con un carácter nulo, junto con xargs -0 para que ambos extremos utilicen el mismo delimitador robusto.
Por último, cpio es un comando menos conocido que tar, pero tremendamente flexible para trabajar con flujos de archivos vía pipes. A diferencia de tar, está pensado desde el inicio para operar con redirecciones y tuberías: recibe una lista de archivos por stdin (normalmente generada con find) y produce o consume archivos de tipo “paquete” sin compresión propia, que luego puedes comprimir con gzip o similares.
Los modos principales de cpio permiten crear archivos (-o), copiar árboles de directorios (-p) o extraer contenidos (-i, a menudo mencionado como “copy-in”). Opciones como -u para sobreescribir, -m para preservar marcas de tiempo o -d para recrear la estructura de directorios hacen posible controlar con detalle qué se copia y cómo, especialmente útil en scripts complejos donde tar se queda corto.
Diseño y optimización de pipelines CI/CD en servidores Linux
Más allá de la línea de comandos tradicional, el concepto de pipeline se ha vuelto fundamental en el mundo de la Integración Continua y Entrega Continua (CI/CD). En un servidor Linux, un pipeline CI/CD es una secuencia automatizada de pasos: obtener el código, instalar dependencias, compilar, ejecutar pruebas, empaquetar artefactos y desplegar.
Linux es especialmente adecuado para esto porque destaca por su rapidez, estabilidad y ecosistema de herramientas de automatización. Plataformas como Jenkins, GitHub Actions o GitLab CI se apoyan en ejecutores Linux (máquinas físicas, virtuales o contenedores) para ejecutar las canalizaciones de forma consistente.
Optimizar estos pipelines implica no solo que “funcionen”, sino que lo hagan con la menor fricción posible. Eso significa reducir tiempos de checkout, minimizar instalaciones repetitivas de dependencias, optimización de imágenes Docker para evitar reconstrucciones innecesarias, reutilizar artefactos ya generados y mantener el entorno seguro y observable.
Una buena práctica básica es estructurar la canalización en etapas bien definidas: build, test y deploy. Lo ideal es compilar una única vez, generar un artefacto (binario, paquete, imagen Docker) que se testea en paralelo en distintas variantes (por ejemplo, varias versiones de lenguaje) y después se promueve el mismo artefacto a entornos de staging y producción, sin volver a compilar.
Trabajar con artefactos inmutables almacenados en repositorios (S3, Nexus, Artifactory, registros de contenedores o paquetes integrados en GitLab/GitHub) simplifica las auditorías, las reversión rápida de versiones y reduce la probabilidad de “funciona en mi máquina pero no en producción”.
Requisitos previos: distribución, usuario de CI y endurecimiento del servidor
Antes de ponerse fino a optimizar millisecond aquí y allá, es importante asentar una base estable en el servidor Linux que actuará como ejecutor de CI/CD. Esto empieza por la elección de la distribución y la configuración mínima de seguridad.
Lo más sensato suele ser estandarizar una distribución LTS o estable que el equipo conozca bien: Ubuntu LTS, Debian Stable o alternativas enterprise como AlmaLinux o Rocky Linux. Tener todos los ejecutores en la misma versión evita comportamientos extraños por bibliotecas o kernels distintos entre jobs.
Otra recomendación es configurar un usuario dedicado para CI, sin permisos de root, con sudo muy limitado solo a los comandos imprescindibles (por ejemplo, systemctl o docker si de verdad hace falta). Este usuario debe autenticarse por claves SSH, tanto para acceder al servidor como para interactuar con repositorios Git u otras máquinas remotas.
A nivel de sistema, conviene mantener el servidor actualizado y mínimamente reforzado. Esto incluye aplicar actualizaciones de seguridad, configurar un cortafuegos restrictivo (por ejemplo con UFW: denegar todo lo entrante salvo lo necesario y permitir salidas), habilitar herramientas como fail2ban para frenar ataques de fuerza bruta a SSH y ajustar algunos parámetros de red y kernel vía sysctl para mejorar fiabilidad y rendimiento.
Por ejemplo, es común elevar el límite de inotify para que los sistemas de build que vigilan muchos archivos no se queden sin recursos, y ajustar el parámetro vm.swappiness para que el kernel sea más conservador al usar swap, algo especialmente relevante cuando los jobs de CI consumen mucha memoria de forma puntual.
Cachés, Docker y paralelización: las palancas de rendimiento en CI/CD
Si miras dónde se va realmente el tiempo en un pipeline medio, verás que una parte enorme se pierde en instalar dependencias y reconstruir imágenes Docker. Atacar esto suele dar más resultado que optimizar el código de los tests unos milisegundos.
La primera palanca es el caching de dependencias. Casi todos los gestores (pip, npm, Maven, Gradle, módulos de Go, etc.) usan directorios de caché locales. En un servidor Linux permanente, puedes compartir esos directorios entre jobs o montarlos en un volumen persistente. Así, cada ejecución no tiene que descargar medio Internet otra vez.
Para Docker, habilitar BuildKit y estructurar bien el Dockerfile marca un antes y un después. Poner la instalación de dependencias justo después de copiar el archivo de requisitos, y antes del resto del código, hace que las capas se reutilicen mientras no cambien las versiones de esas dependencias. Además, se pueden montar caches específicos para pip, npm, etc., dentro del propio build.
La segunda gran palanca es la ejecución de pruebas en paralelo. Muchos frameworks soportan concurrencia de forma nativa: pytest con -n auto, herramientas de Java como Surefire, Jest en JavaScript con --maxWorkers, etc. Dividir la suite por módulos, carpetas o incluso por tiempo estimado y balancearla entre varios workers permite reducciones de 2 a 5 veces en la duración de la fase de tests sin cambiar ni una línea de negocio.
Por último, está la cuestión de los artefactos y la promoción. En vez de recompilar la misma imagen para staging, preproducción y producción, lo eficiente es build una vez, guardar el resultado en un repositorio y etiquetarlo según el entorno al que se despliega. Eso reduce consumo de CPU, evita inconsistencias y acelera mucho las canalizaciones largas.
Optimización de Jenkins, GitHub Actions y GitLab Runner en Linux
Cada sistema de CI tiene sus particularidades, pero todos se benefician de las mismas ideas básicas cuando corren sobre Linux. La clave suele estar en usar ejecutores efímeros y limpios, mantener un espacio de caché persistente bien dimensionado y controlar la concurrencia.
En Jenkins, una práctica muy común es utilizar agentes ligeros y temporales (por ejemplo, contenedores Docker o pods en Kubernetes u otras soluciones de orquestación de contenedores) para ejecutar los jobs, mientras que el nodo maestro se mantiene lo más simple posible. Los agentes pueden configurarse como servicios systemd en servidores Linux, registrándose en el controlador y levantándose automáticamente al arrancar la máquina.
Para GitHub Actions con runners autoalojados, es recomendable desplegarlos en máquinas virtuales Linux con SSD rápidos, colocar un directorio de caché grande y dedicados a las acciones (dependencias de lenguajes, caches de builds, etc.) y limitar la cantidad de jobs simultáneos para no saturar CPU ni disco. Aprovechar la acción de caché oficial con rutas como ~/.cache/pip, ~/.npm o ~/.m2 marca una diferencia enorme en tiempos.
En GitLab Runner, elegir entre ejecutor shell o Docker depende del equilibrio entre rendimiento y aislamiento que necesites. El shell executor es más rápido porque se ejecuta directamente en el host, pero el Docker executor ofrece entornos limpios y replicables. Puedes además configurar caché compartida (local o en S3) y ajustar el número máximo de jobs concurrentes para aprovechar el hardware sin ahogarlo.
En todos estos casos, tener volúmenes compartidos para caché de dependencias y, a la vez, evitar que los workspaces se ensucien entre builds es fundamental. Las máquinas o contenedores efímeros, que se crean y destruyen con cada pipeline o cada grupo de pipelines, reducen enormemente los problemas de “funcionaba ayer y hoy no” por residuo de compilaciones previas.
Rendimiento del servidor Linux: CPU, memoria, E/S y Docker
Por muy optimizados que estén tus scripts, si el servidor Linux que ejecuta la canalización no está bien dimensionado, te vas a encontrar con colas eternas y trabajos que se arrastran. Una configuración típica razonable para un equipo medio son 4-8 vCPU y 8-16 GB de RAM, con almacenamiento SSD (idealmente NVMe) y algo de swap (2-4 GB) para soportar picos sin matar procesos agresivamente.
El sistema de archivos también importa. Usar ext4 o XFS con la opción noatime en los volúmenes donde compilas o escribes logs reduce E/S innecesaria. Además, montar un tmpfs para archivos temporales o artefactos de corta duración (por ejemplo, /mnt/ci-tmp) acelera operaciones intensivas y evita que el disco se llene de ficheros residuales entre jobs.
En cuanto a Docker, la higiene del daemon es clave. Eliminar imágenes y volúmenes no utilizados de forma segura y periódica, manteniendo al mismo tiempo las imágenes base calientes, ayuda a controlar el espacio de disco y los tiempos de arranque. Comandos como docker system prune con filtros temporales adecuados permiten limpiar sin cargarse recursos usados recientemente.
Si tu CI es muy intensivo en contenedores, también puedes recurrir a registros espejo para evitar descargar siempre desde Internet, usar BuildKit para concurrencia y caché de capas, e incluso configurar afinidades de CPU (CPU sets) o nodos dedicados para los ejecutores más exigentes, evitando interferencias entre cargas de trabajo vecinas. Además, entender la microarquitectura de CPU ayuda a dimensionar mejor los recursos para cargas CI intensivas.
Seguridad en el pipeline (DevSecOps) y despliegues en Linux
Un pipeline rápido pero inseguro es una bomba de relojería. Integrar la seguridad en la propia canalización y la seguridad en contenedores Docker es ya un estándar en cualquier estrategia DevSecOps, y Linux ofrece muchas herramientas para ello.
Lo primero es tratar los secretos y credenciales con máximo cuidado. Nunca deben vivir en el código ni en archivos de configuración versionados. En su lugar, se almacenan en gestores de secretos (variables enmascaradas de GitLab, secretos cifrados de GitHub, HashiCorp Vault, etc.) y se inyectan solo durante la ejecución del job que los necesita, con tokens de corta duración cuando sea posible.
Otra capa importante es la generación de SBOM (Software Bill of Materials) y la firma de artefactos. Herramientas como Syft o CycloneDX permiten enumerar todos los componentes que forman parte de una imagen o binario, mientras que Cosign u otras soluciones de firma verificable aseguran que solo se despliegan artefactos que han pasado por el pipeline y han sido validados.
En la parte de red y acceso, conviene segmentar las redes de CI y de producción, aplicar firewalls estrictos, auditar los logs de ejecución y rotar credenciales de forma periódica. Donde haya SSH, mejor usar certificados o claves con caducidad que contraseñas estáticas.
A la hora de desplegar sobre Linux, las estrategias como Blue/Green, rolling y canary reducen muchísimo el impacto de errores de despliegue. Ejecutar la aplicación como servicio systemd, colocar un Nginx o HAProxy delante, y controlar el tráfico entre versiones mediante checks de salud te permite lograr prácticamente cero tiempo de inactividad durante actualizaciones.
Por ejemplo, al recargar Nginx y reiniciar servicios con systemd usando señales de parada suave (como SIGTERM) y tiempos de espera razonables, puedes lograr que las conexiones activas se drenen antes de que el proceso se detenga, manteniendo la experiencia del usuario intacta mientras cambias de versión en segundo plano.
Observabilidad, métricas y costes en pipelines Linux
Una vez que tienes tus pipelines funcionando, el siguiente nivel es medirlos y entender dónde se va el tiempo y los recursos. No basta con saber si un workflow pasa o falla; hay que monitorizar la duración de cada etapa, el tiempo de cola, la tasa de éxito, la frecuencia de despliegues, la tasa de aciertos de caché, etc.
Es habitual exportar métricas de sistema mediante node_exporter, centralizar logs con soluciones tipo ELK o Loki, y visualizar todo en paneles de Grafana. De esta forma puedes detectar si, por ejemplo, la fase de tests ha aumentado su duración un 30 % en la última semana o si los jobs pasan demasiado tiempo esperando ejecutor disponible; el monitoreo de tráfico de red con herramientas de código abierto complementa esa visibilidad.
También es posible instrumentar el propio pipeline, por ejemplo en GitHub Actions o GitLab CI, para medir programáticamente cuántas ejecuciones han sido exitosas, cuánto ha durado cada run y cuál es el estado global. Un script que llame a la API del proveedor, compute el número total de runs, las que han acabado con éxito, las fallidas, la tasa de éxito y la duración media, y guarde todo en un JSON (como pipeline-metrics.json) permite integrar esas métricas en informes o paneles de control.
Con esa información puedes tomar decisiones sobre tamaño y número de runners: a veces es mejor tener más ejecutores pequeños que pocos muy grandes, para reducir tiempos de espera. La autoescalabilidad —por ejemplo, autoscaling en la nube o pools dinámicos de nodos Kubernetes— ayuda a absorber picos de actividad durante el día y minimizar recursos infrautilizados por la noche.
Estas prácticas no solo mejoran la experiencia del equipo, sino que ayudan a ajustar costes de infraestructura, controlando el consumo de CPU, memoria y, muy especialmente, de almacenamiento, que suele dispararse con imágenes y cachés si no se limpia de forma regular y planificada.
Dominar tanto los pipes clásicos en la línea de comandos como los pipelines modernos de CI/CD en Linux ofrece una combinación muy potente: puedes automatizar desde tareas simples de filtrado de texto hasta complejas canalizaciones de construcción, pruebas y despliegue mantenibles, seguras y rápidas. Entender cómo fluye la información entre procesos, cómo se cachean las dependencias, cómo se afinan los servidores y cómo se integran métricas y seguridad te permite construir flujos de trabajo que escalan con tu equipo y tus proyectos sin convertirse en un cuello de botella constante.

Tabla de Contenidos
- Qué es un pipeline y cómo encajan los pipes en Linux
- Entendiendo stdin, stdout y el flujo de datos
- Uso práctico de pipes en la terminal de Linux
- Comandos avanzados para sacar partido a los pipes: tee, xargs y cpio
- Diseño y optimización de pipelines CI/CD en servidores Linux
- Requisitos previos: distribución, usuario de CI y endurecimiento del servidor
- Cachés, Docker y paralelización: las palancas de rendimiento en CI/CD
- Optimización de Jenkins, GitHub Actions y GitLab Runner en Linux
- Rendimiento del servidor Linux: CPU, memoria, E/S y Docker
- Seguridad en el pipeline (DevSecOps) y despliegues en Linux
- Observabilidad, métricas y costes en pipelines Linux